

AI Voice Agent Monitoring: Post-Call Analytics Playbook for 2026
Date
Jun 17, 26
Reading Time
10 Minutes
Category
AI Voice Agents
Share

Your call success rate shows 98%. Average latency: 450ms. Error rate: 0.2%.
And yet escalations are climbing. Customers keep calling back. Your VP of CX is asking questions you can't pull from a dashboard.
That's the paradox most teams building AI voice agents run into. The numbers look healthy because they are measuring the wrong things.
Proper AI voice agent monitoring isn't transcript logging with a better interface. Transcripts tell you what was said. They don't tell you which pipeline layer broke, or why a call that "completed successfully" still generated a callback 20 minutes later.
Teams using transcript-only setups catch production failures 2 to 3 days after customers experience them. Teams with proper observability catch them in minutes.
That gap shows up in your churn numbers before your dashboard sees anything, especially if you've deployed across any of the major voice services at scale.
Post-call analytics is where AI voice agent monitoring actually starts. And it covers a lot more ground than most teams expect.
Logging Transcripts Is Not the Same as Monitoring Your Agent
Monitoring a web app by logging HTTP 200 status codes is basically useless. You know requests completed. You don't know why 8% of users got a 4-second load time, or why checkout broke on mobile at 11 pm. Call logs work the same way. A conversation "completed." Great. Why did the caller ring back 20 minutes later?
Transcripts are call logs with more text. Once you've built your agent and calls are flowing, having transcripts feels like AI voice agent monitoring. It isn't.
Four things transcripts will never surface:
- Audio degradation: packet loss, jitter, and codec issues at the telephony layer. The conversation text looks fine. The caller heard garbled audio for 3 seconds and couldn't catch the confirmation number.
- Component latency breakdown: Was that a 1.2-second pause in the STT? The LLM? The TTS? Your transcript has no record of the source of the delay.
- TTS synthesis drift: your agent started sounding robotic after a provider update. No alert fired. Satisfaction scores quietly dropped over two weeks.
- ASR confidence decay: transcription accuracy that slowly declines for specific accents or noisy environments. The words look plausible in the text. The intent classification is off by 12 points.
A voice agent runs on a layered voice AI stack where telephony, transcription, the language model, and speech synthesis each operate independently. Each layer fails on its own. And most of those failures never show up in the text.
Real AI voice agent monitoring covers the whole pipeline. Post-call analytics that only read transcripts are missing three of the four places your agent can actually break.
What transcripts miss: audio quality at the network layer, component-level latency breakdown, TTS regression, silence events, barge-in failures, and ASR confidence drops. These are the signals that explain why calls fail.
Four Layers, Four Ways Your Agent Can Break Without You Knowing
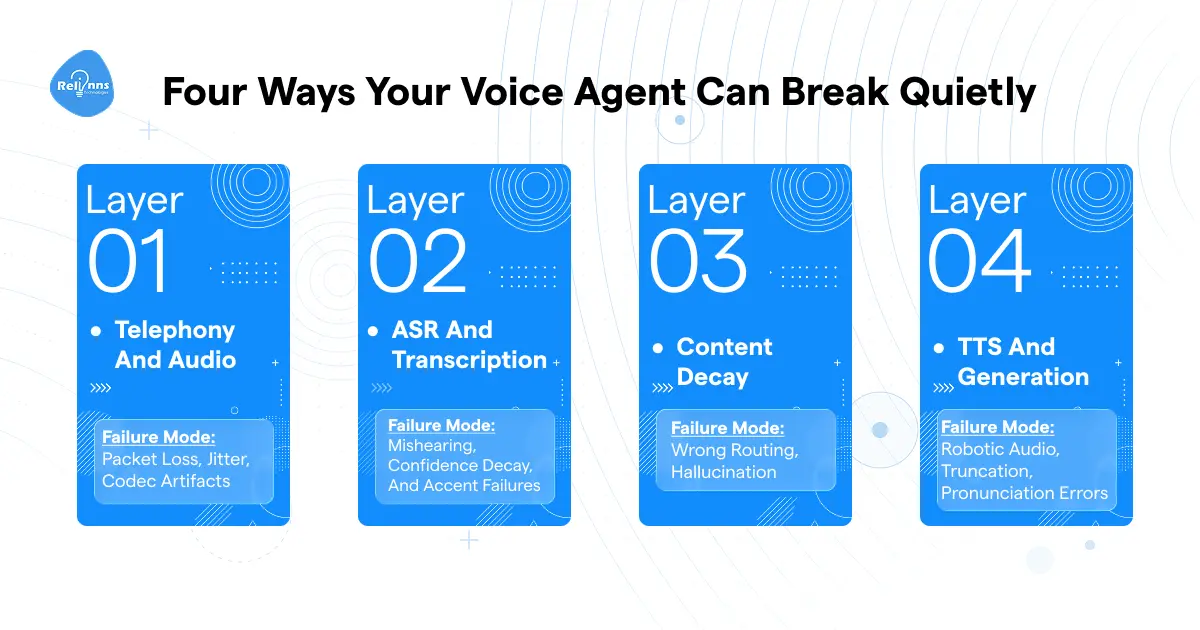
Most teams set up AI voice agent monitoring as if the whole thing were a single unit. Call completion rate up, error rate down. That assumption holds until something breaks at layer 2 while layers 3 and 4 keep reporting green.
A voice agent isn't one system. It's four systems running in sequence: Telephony and Audio, ASR and Transcription, the LLM semantic layer, and TTS generation. Each one fails on its own. And most of those failures don't show up in your call outcomes.
Here's what a real cascade looks like. You get 3% packet loss at the telephony layer. Not enough to drop the call. The ASR receives corrupted audio and misses a keyword. The LLM gets an incomplete transcript, misclassifies intent, and routes the caller to the wrong flow. The caller hangs up, frustrated. Your dashboard logs a completed call.
No alert fired. The post-call analytics just show a call that ended.
Latency optimization surfaces this at another level. The industry median Time to First Word is 1.4-1.7 seconds. The human conversational expectation is 300ms. That's a 5x gap that transcripts will never surface. The damage lives in the p95 tail, invisible to your average latency metric.
An AI voice agent monitoring that doesn't map to the stack will always chase symptoms instead of causes.
Expert Tip: Cascading failures are the hardest to diagnose because each layer looks healthy on its own. 3% packet loss at the audio layer won't trigger any alerts, but it produces enough ASR errors to reduce intent accuracy by 8 to 12 points. Map failures to the layer that caused them, not the layer that showed the symptom.
The four layers explain where failures hide. The metrics most teams track are a separate problem, and in some ways a worse one.
The Metric That Looks Like Success (And Isn't)
Containment rate is the metric most teams cite when their AI voice agent monitoring looks healthy. High containment, fewer escalations, lower agent costs. The automation is working.
That logic holds until you look at what's sitting underneath it.
Containment rate measures one thing: whether a call ended without a human getting involved. It says nothing about whether the caller actually got what they came for.
Lead qualification is a clean example. An agent who deflects 85% of calls might be answering questions well or wearing callers down until they give up. Both scenarios produce the same containment number.
That's false containment. And it's more common than most teams want to admit.
"Optimizing containment alone can prioritize cost over resolution quality. High containment with low CSAT indicates false containment: users giving up rather than getting helped."
Track containment rate alongside task completion rate. Containment tells you what the agent handled. Task completion tells you whether you solved the problem. The gap between those two numbers is where your churn is hiding.
The latency version is the same trap. A 450ms average looks fine. But if 10% of calls spike to 1,500ms, that's 1,000 bad experiences a day at 10,000 call volume. Average metrics absorb tail failures without flagging them.
Post-call analytics that don't separate these two dimensions won't catch false containment until it's already showing up in callbacks.
Comparing AI voice agents to human agents solely on containment is how teams convince themselves that automation is working, while customers quietly leave. For outbound calling campaigns, it's even harder to catch because there's no inbound callback to measure against. And what voice agents cost looks justified on paper until the churn data catches up.
Proper AI voice agent monitoring tracks both columns. The next section covers which specific numbers to alert on.
What AI Voice Agent Monitoring Actually Looks Like in 2026
The fix isn't a better dashboard. It's instrumentation that maps to the actual stack.
Each of the four layers needs its own thresholds and its own alerts. Not a single "call health" score that averages across everything. When something breaks, you need to know which layer broke it.
Start with latency. These are the production targets that hold up at scale:
Expert Tip: The LLM layer accounts for roughly 70% of total voice latency. Before touching STT or TTS config, audit your LLM first: model selection, prompt length, and output caching will move the overall number faster than anything else downstream.
Barge-in is the metric most teams skip, and it's a mistake. A barge-in failure is the single most disruptive thing a caller can have. The agent keeps talking after they try to interrupt. The conversation falls apart. Anything below 80% success rate should fire an immediate alert.
Action Item: Stop tracking the average Time to First Word. Switch to p95. A 300ms average can hide 10% of calls sitting at 1,500ms. At 500 daily calls, that's 50 terrible experiences your dashboard isn't showing you.
When you're scaling your voice agent past a few hundred daily calls, the thresholds stay the same, but the alerting strategy shifts. A single p95 spike at low volume is an edge case. The same spike at high volume is a pattern with a specific root cause.
Call direction changes the benchmarks, too. Inbound vs outbound voice AI need different containment definitions, different escalation thresholds, and SLA baselines. Set up AI voice agent monitoring to separate the two flows. An outbound call that hands off to a human might be a success. An inbound call that does the same thing is often a failure.
Post-call analytics that treat both identically will fire alerts that mean nothing and miss the ones that do.
The Six Numbers That Tell You If Your Agent Is Actually Working
Six metrics. That's the full AI voice agent monitoring set you need to track consistently.
Not twenty. Not a custom scoring model. Six numbers, tracked against clear thresholds, will surface most production failures before your customers do.
The WER row needs context. Standard WER treats all transcription errors the same. "Gonna," transcribed as "going to," and a medication name, transcribed, both count as one error. For multilingual voice agents or any healthcare deployment, that equivalence is dangerous. Semantic WER only penalizes errors that change what the LLM does with the transcript. Track that version.
FCR measurement is where most teams get it wrong.
A caller who rings back within 48-72 hours about the same issue is a failed resolution, even if the original call was logged as complete.
AI call center agents use this window as standard practice. Most out-of-the-box dashboards don't set it correctly.
Containment benchmarks also vary more than people expect. Check how your contact center providers define and report it before accepting their numbers. An appointment booking agent at 65% containment is underperforming. A complex billing dispute agent at 65% might be doing well. Context matters.
When detecting angry callers via sentiment signals, the data feeds your satisfaction proxy and helps explain task-completion failures that the transcript alone won't show.
Bottom line on post-call analytics cadence: track all six. Alert on two immediately: TTFW p95 and task completion rate. Review the other four weeks. That rhythm catches most failure patterns before they compound.
Comparisons between human receptionists and voice agents often inflate containment targets unrealistically. Set yours against your actual use case, not an industry average.
Building a Post-Call Evaluation Loop That Doesn't Drown You in Data
Someone running a small voicebot setup put it well in a Reddit thread on this topic: "It's plain old recordings and goal assertion. That's it. Don't overcomplicate it."
That's the right starting point. Not a scoring framework. Not a 40-widget dashboard. A recording of every call and a pass/fail check against a success criterion you defined before the call went live.
The keyword is "before." When building a voice AI knowledge base or setting up voice agent guardrails, first write down what success looks like for each call type. Make it machine-checkable. If you can't describe it in one sentence, your evaluation will produce noise regardless of the tools behind it.
Don't collapse task success and customer satisfaction into one number. They're different things.
LLM-as-judge achieves 95%+ agreement with human raters when calibrated correctly. Run it async after each call, not inline. The score doesn't need to land before the next turn starts.
For agentic RAG updates or changes to voice AI prompts, re-run evaluations on a fixed test set before pushing anything live. That's the core of regression testing your voice agent at scale without manual review.
Expert Tip: Force your LLM judge to write a rationale before the verdict. "Failed because the agent didn't confirm the booking date" is a debugging artifact you can act on. Just "fail" is useless data. This practice also helps with preventing voice agent hallucinations in the eval layer by checking whether the rationale actually connects to something in the transcript.
Above 1,000 calls a day, 200 failed calls mapped to 8 root-cause clusters are manageable. 200 individual transcript reads are not. Cluster first, then review.
For teams running AI agents and AI chatbots alongside voice, BotPenguin tracks conversation outcomes across 10+ channels from one place. Intent failures in chat or WhatsApp often appear 24 to 48 hours before the same pattern hits voice. That cross-channel post-call analytics view catches problems earlier than single-channel AI voice agent monitoring ever will.
SLOs, Alerts, and Why You Should Never Page the Wrong Team
Voice SLOs differ from text-based ones in one important way: audio quality and response quality are separate axes. A latency breach and an ASR accuracy drop need different teams and different response windows.
Three tiers that work for production AI voice agent monitoring:
Hard gates. PII and PHI redaction failures, safety assertion violations, HIPAA-compliant voice agent breaches. Zero tolerance. Immediate page on any occurrence.
Active incidents. TTFW p95 above 800ms for 5+ consecutive minutes. Task completion is dropping 10 points per hour. These pages.
Drift signals. Task completion is trending down 5% over 7 days. WER is climbing in one accent segment. These go to Slack for weekly review, not an on-call rotation.
Route by issue category. STT failures go to the audio team. LLM intent regressions go to whoever owns the model. Voice agent privacy and security violations go to compliance. Routing everything to one person means two hours of triage before the right team even knows there's a problem.
The teams that debug fastest aren't the ones with better engineers. They're the ones whose alerts land with context already attached: which layer, which component, what changed. Good AI voice agent monitoring makes that automatic.
Post-call analytics that produce alerts without context are just a louder version of the same problem.
Start with Recordings. Build from There.
The gap between catching failures in minutes vs days comes down to layer-aware AI voice agent monitoring, not tool spend.
Start with the floor: a recording of every call, plus a pass/fail check against a success criterion you defined before deployment. That setup catches roughly 70% of production failures without any complex tooling.
Then layer in TTFW p95, task completion rate, and barge-in success once call volume stabilizes.
Relinns builds AI voice agents on Retell AI for customer service, healthcare, insurance, logistics, ecommerce, and restaurants, and sets up the full monitoring stack alongside the build.



