

How to prevent your AI Voice agent from Hallucinations? The Truth
Date
Jun 16, 26
Reading Time
12 Minutes
Category
AI Voice Agents
Share

Your AI voice agents went live three weeks ago. The voice sounds good. Customers are calling. Then your inbox gets a ticket: the agent told someone you have offices in cities you don't operate in, a return window you've never offered, and a feature that doesn't exist. It said all of it with complete confidence.
That's what voice agent hallucinations look like in production. Not vague answers. Confident fabrications.
Voice AI hallucinations hit differently than chatbot errors. The customer had no way to fact-check in real time. They just believed it and acted on it.
Most teams try the obvious fix: tighten the system prompt, add guardrails, re-test. It holds. Then it breaks again.
Prompt fixes won't solve this. Voice agent hallucinations are a pipeline and architecture problem. This post covers where they actually come from and what genuinely stops them.
Your Voice Agent Is Making Things Up. Here's What That Actually Looks Like.
Voice agent hallucinations aren't vague answers. They're confident, completely wrong statements delivered in a natural voice, with zero hesitation.
Three patterns show up in production.
Confabulated facts.
A Retell AI developer posted about this: their agent was telling callers "we have outlets in Mumbai and Delhi" when the business had exactly one location, in Hyderabad. The agent invented branches because nothing in the knowledge base said otherwise. It filled the gap with something plausible.
Workflow deviation.
The agent skips a required step or adds one that doesn't exist. In customer service calls, that's a bad experience. In a regulated environment, skipping a mandatory disclosure and inventing an approval step carries equal legal weight. Both are violations.
Commitment drift.
"I'll have someone call you within the hour." "You're approved." "We'll waive that fee."
These are promises the business never authorized. In some jurisdictions, those commitments are legally binding regardless of whether the AI had authority to make them.
That's what voice agent guardrails are supposed to catch, and most deployments go live without them configured for this specific failure mode.
The table below maps each type of voice agent hallucination to the business risk it poses.
"A chatbot hallucination is embarrassing. A voice hallucination is a liability."
Voice AI hallucinations follow predictable patterns. These three look different on the surface, but they share one root cause. And it's not your model. It's the medium itself, and that changes everything about how you fix this.
Why Voice Is Completely Different From Text (And Why You Can't Prompt Your Way Out of It)
The conventional wisdom goes like this: hallucinations are a model quality problem. Better LLM, tighter prompts, lower temperature. Fixed.
That's true enough for text. For voice agent hallucinations, it's not close to sufficient.
A text hallucination is recoverable. A chatbot response is something the customer can re-read, screenshot, and fact-check. A voice agent's response evaporates the moment it's spoken. The customer's memory becomes the only record, and that memory often differs from what was actually said. There's no scroll-up.
Voice AI hallucinations also carry a trust premium that text doesn't. A confident voice signals authority. Customers believe what a human-sounding agent tells them more readily than what they read in a chat window. The same wrong answer lands harder in voice because it registers as more credible.
Then there's the compliance layer. Many regulated phone interactions carry phone-specific legal obligations that chat never had. HIPAA-compliant voice calls in healthcare operate under different rules than a chat session with the same content.
Any agent mishandling PII and PHI in voice during a clinical intake call creates breach-level exposure, not just a correction ticket. In voice agents for insurance and collections workflows, a hallucinated statement about coverage or debt status can trigger a regulatory complaint that the equivalent chatbot error never would.
The compliance and security exposure in voice is wider than most build teams account for at launch.
When you trace where voice agent hallucinations actually originate, it's not a model problem. It's a pipeline problem that requires architectural decisions at every layer, from how audio gets transcribed to how actions get verified before the agent speaks.
So if the problem runs deeper than prompts, what's causing it? There are three root causes, and most builders focus on only one.
The Three Root Causes (That Aren't Just Bad Prompts)
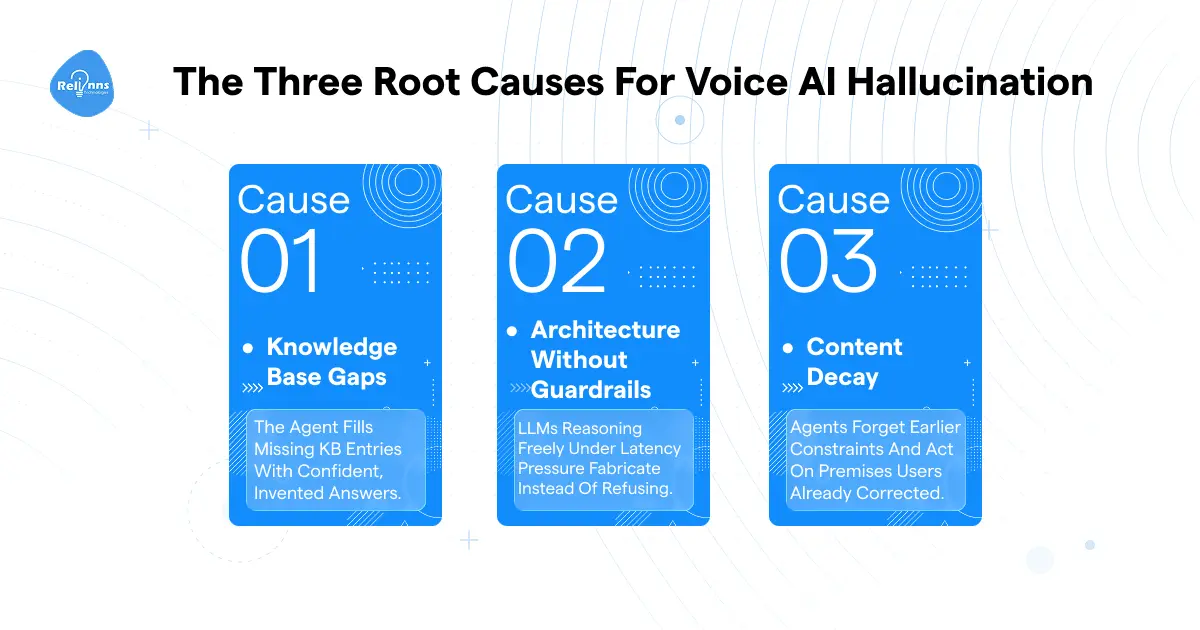
The three root causes of voice agent hallucinations aren't what most teams are spending their time on.
1. Knowledge base gaps are the easiest to fix.
The agent gets asked something its KB doesn't cover, and instead of saying "I don't know," the LLM produces a plausible-sounding answer.
That's exactly what happened with the Retell builder's fake branch locations from Section 1: the KB had a gap, and the LLM filled it confidently.
The fix is operational, not technical. Someone must own building a voice AI knowledge base as an ongoing responsibility, not a launch task that gets closed the day you go live.
2. Architecture without guardrails is trickier than it looks.
The obvious version is an LLM reasoning freely under latency pressure. But the less obvious version is that hallucination often starts at the ASR layer, before the LLM is even involved. Noisy audio and homophone errors produce a corrupted transcript. And how LLMs generate responses means the model then reasons confidently on that bad input. The LLM isn't lying. It's working with fabricated data.
3. Context decay is the biggest one in production.
In multi-turn conversations, the agent forgets a constraint stated four turns back, or acts on a premise the user already corrected. Voice AI hallucinations in this category aren't knowledge gaps.
There are memory gaps. The LLM fabricates parameters that contradict the caller's own history. This is the largest class of voice agent hallucinations in real multi-turn deployments.
Knowing the causes is half the job. The other half is a harder conversation about the platform and architecture you chose to build on, because that choice determines whether you can apply the fixes we're about to cover.
Your Platform Choice Has More to Do With This Than You Think
Most teams pick their voice platform the way they pick a CRM: fast demo, good docs, ship it. The assumption is that a managed platform is roughly as good as another at controlling hallucinations.
That assumption will cost you in production.
Managed platforms like Retell and Vapi get you to deployment fast. But they abstract away the exact layers where guardrail intervention lives. If your ASR misreads an entity, you can't insert custom filtering logic between the transcription and LLM on a fully managed stack. The abstraction that saves you time at launch becomes a ceiling when voice agent hallucinations become a production problem.
Most voice AI hallucinations in regulated deployments trace back to the platform choice made on day one.
Pipecat exposes the voice agent as a directed pipeline graph. Every stage is code you control. You can run sentiment analysis in parallel with transcription, or insert a semantic router before the LLM sees any input. LiveKit takes an event-driven approach built on a WebRTC-based transport, giving precise control over jitter, buffering, and audio collisions, where ASR errors originate. Both require more implementation depth, but both give you the intervention points that managed platforms don't.
Understanding your full AI voice stack is the prerequisite for knowing which layer you can actually intervene in. Standard customer support? Managed is fine. Healthcare intake, insurance claims, collections? You need pipeline access.
That said, Retell's Conversation Flow feature does real work within its constraints. Node-based structure, with defined conditions between steps; the agent advances only when the criteria are met. It won't give you pipeline-level control. But it reduces voice agent hallucinations meaningfully compared to purely generative conversation. Configure it properly rather than leaving the defaults in place.
The choice you make when building your voice agent sets your ceiling for hallucination control long before you write a single guardrail.
Once you know your architectural ceiling, the next layer is grounding how you actually tether the agent to verified truth at the data and retrieval level. That's where most of the practical engineering work lives.
Grounding and RAG: How to Actually Anchor Your Agent to the Truth
Grounding is the mechanism that keeps voice agent hallucinations from originating in the first place. It means binding output to verified, current, external data rather than whatever the LLM learned during training. The two ways to do this are a well-maintained knowledge base and Retrieval-Augmented Generation.
Start with the KB. KB health is the single biggest predictor of hallucination rate, not your model choice, not your prompt. A KB that hasn't been updated in three months is a hallucination waiting to happen. Retell's knowledge base automatically rewrites recent conversations into a standalone search query before each retrieval, which is genuinely useful. But it also means your query-rewriting needs testing on real calls, not on clean demo scripts. Indirect references like "that plan" or "the thing from earlier" consistently break naive rewriting.
Now the part most teams skip: RAG and voice agent latency are directly connected. Standard RAG adds 50-300ms to the critical path. Add LLM time-to-first-token (400-800ms) and TTS synthesis (150ms), and you're past 1.5 seconds total. ElevenLabs' own documentation puts their RAG latency addition at roughly 250ms.
Once you cross 1.5 seconds, users assume the agent didn't hear them and start re-speaking. The overlapping audio breaks the ASR buffer. The chain reaction that produces voice AI hallucinations due to a latency spike rather than a knowledge gap is real and common.
A few rules that actually hold in production. Keep the retrieved chunk set small and rerank it. Fewer chunks reduce latency but hurt answer quality if you skip reranking. Keep the spoken answer short and store the full evidence separately. TTS should never receive raw document dumps. Capture citation IDs for every answer, even if you don't speak them aloud.
The underlying principle: treat speech as the final rendering layer, not the reasoning layer. Generate a structured draft, ground it with retrieval, verify claims against the source, then synthesize a short spoken utterance. That sequence stops voice agent hallucinations from reaching audio output at all.
One more thing on context. Never exceed 50% of your max context window in multi-turn conversations. Past that threshold, model behavior drifts, and context decay errors start compounding fast.
Grounding Pre-Launch Checklist
Before going live, check:
- Is your KB current and version-controlled?
- Is someone explicitly assigned to update it when products or policies change?
- Have you tested RAG retrieval latency against real conversational pacing, not clean inputs?
- Are you keeping spoken answers short and separate from the full evidence trace?
- Are you staying under 50% of the context window in multi-turn conversations?
- Have you tested query rewriting on calls with indirect references?
Grounding handles what the agent says. Deterministic controls handle what the agent decides. That second layer is where most builders leave their biggest exposure.
Deterministic Controls: Give the LLM a Voice, Not a Vote
The cleanest mental model I've found for this: deterministic code is the brain, the LLM is the mouth. The mouth never decides. It only speaks.
Most voice agent hallucinations at the logic layer occur because the LLM is asked to make decisions it shouldn't make. Routing calls, choosing tools, and interpreting ambiguous entities. Route those decisions through deterministic code. Reserve the LLM for what it's actually good at: understanding natural language, phrasing responses, recognizing intent from imperfect speech.
One thing that gets underestimated: a large percentage of "wrong answer" hallucinations are actually wrong entity hallucinations. The agent misheard an account number, an order ID, a name. Treat high-precision fields as requiring explicit confirmation before any tool call fires. For numeric IDs specifically, read them back digit by digit. This is one of the highest-leverage practical changes you can make to reduce voice agent hallucinations in production.
And when audio is unclear, the agent asks for clarification. It doesn't infer, doesn't guess, doesn't call tools. Every voice system needs a short clarification branch and a retry budget before any lookup or action runs. Most builders skip this because it feels like friction. It isn't. Unclear audio handling is the most underbuilt layer in production voice AI hallucination prevention.
For write actions such as booking appointments, processing payments, or issuing refunds, the agent summarizes the intended action and confirms it before executing. It only claims success after the tool call succeeds. Not before.
Compliance flows are a separate category entirely. Mini-Miranda disclosures, payment authorizations, and identity verification. These must run on deterministic logic, not generative reasoning. The LLM is the wrong tool for any step that has to be exact every time.
On abstention: engineer "I don't know" as a success condition in your system prompt. The voice AI prompting guide covers the full prompt skeleton, but the principle is simple: uncertainty disclosure is a success state, not a failure. The agent should be explicitly instructed to say it doesn't have enough information to answer accurately.
The LLM you choose affects your baseline hallucination rate, but temperature configuration matters as much as model selection. It's the variable most enterprise deployments leave at the default.
When you're building agentic voice workflows with structured conversation logic, appointment booking, document collection, and multi-step qualification, BotPenguin separates conversation routing logic from generative response output. That separation is exactly the deterministic-brain, LLM-mouth principle in practice.
Architecture and grounding handle the structural causes. But a large fraction of voice agent hallucinations only surface under real production load, real call volume, real background noise, and real edge cases. That's where operational safeguards become the last line of defense.
What Production-Grade Hallucination Prevention Actually Looks Like

1. Run QA on 100% of calls, not a 5% sample.
AI-driven scoring surfaces hallucinate patterns within hours, not weeks. At 5% sampling, a systematic error can run for two full weeks before you've flagged enough calls to see the pattern. By then, it's already a complaint queue, not a catch.
2. Build confidence-triggered escalation on day one.
The agent should hand off not only when a user asks for a human, but when its own confidence score drops below a threshold you define. Knowing exactly when to hand off to a human agent is a design decision. Don't bolt it on after the first bad call.
3. Monitor escalation rates and sentiment in real time.
Dashboards that detect customer frustration and track escalation spikes give you the earliest signal that something in the KB or guardrail logic has drifted. You want to catch that before your customers do.
4. Sample real production calls every week.
Compare against ground truth. Adjust prompts, guardrails, and thresholds based on what you actually find, not what you assumed at build time. Most regressions are visible in call samples before they show up in NPS scores.
5. Assign a named KB owner with a defined update schedule.
Unowned knowledge bases are the most consistent source of voice AI hallucinations in production deployments. A KB that worked at launch drifts as your products, policies, and pricing change. Without a named owner and a real schedule, even a well-architected agent starts fabricating within months. This becomes non-negotiable as you scale voice agent operations at higher volumes across multiple verticals.
"The single biggest predictor of hallucination rate is knowledge base health, not your model choice."
For sensitive escalations, human intervention is part of the design, not a fallback. The goal is routing it to where it matters. Skipping that framing is how you end up with voice agent hallucinations; the system had no path to catch.
Operations keep the system honest. But without the right measurement, you're running blind. The metrics most teams track won't show you where your agent is hallucinating. What follows is what to track instead.
How to Know if Your Agent Is Getting Better or Getting Worse
Average latency is a deceptive number. A 500ms average can mask that 10% of your calls are hitting 3-second spikes. At those spikes, users re-speak. Overlapping audio breaks conversational state. The ASR receives garbled input, which produces downstream voice AI hallucinations, not due to a knowledge gap but to a timing failure. Track percentiles, not averages.
Five metrics actually tell you whether you're controlling voice agent hallucinations or just hoping. Faithfulness measures the percentage of claims with a traceable source. HUN Rate catches fluent but completely off-topic outputs. Downstream Propagation measures how often a hallucination makes an incorrect tool call. Downstream Propagation should be 0%.
FactScore verifies the factual accuracy of atomic claims against your KB. Talk Ratio flags agents that dominate the conversation, which correlates with both fabrication risk and poor experience.
For regulated industries like healthcare, downstream propagation and faithfulness aren't optional metrics to track someday. They're the difference between an audit flag and a clean compliance record.
The EVA framework runs regression testing using a bot-to-bot User Simulator over live audio. It catches cascading failures that text-only benchmarks miss entirely, including what happens when a user interrupts the agent mid-sentence.
Voice agent hallucinations aren't a model problem. They're a layered systems problem: architecture, grounding, deterministic routing, abstention pathways, operational QA, and measurement that tracks what actually matters.
None of this is a one-time fix. Hallucination rates drift as KBs age, policies change, and call volumes scale. The teams that get this to near-zero treat it as a continuous discipline.
Relinns builds production-grade voice AI on Retell AI and ElevenLabs with grounding, deterministic flows, and operational QA built in from day one, not retrofitted after the first complaint.



