

PII and PHI Redaction in AI Voice Agents: Detailed Guide for 2026
Date
Jun 13, 26
Reading Time
12 Minutes
Category
AI Voice Agents
Share

Most teams think they've solved PII redaction the moment their transcript viewer shows asterisks. Box ticked. The voice agent tells the caller, "I won't repeat your card number for security," the UI confirms it, and everyone moves on.
But the transcript viewer is the last place to look.
When a caller speaks a card number, that data doesn't go to one system. It travels through nine. Telephony logs, the raw audio stream, the ASR transcription buffer, the LLM context window, function call outputs, both call-recording channels, debug logs, observability traces, and downstream analytics pipelines. Asterisks on screen, original value sitting in six of those nine.
AI voice agents are moving into call flows that carry card numbers, diagnoses, and claim IDs every day. And if you're replacing human receptionists with an automated voice system, the compliance surface didn't shrink when you automated. It multiplied.
PHI and PII redaction in voice AI is an architecture problem. This guide maps every stage where your pipeline leaks sensitive data and tells you what to control at each one. PII redaction done right starts well before the transcript renders.
Before you fix the architecture, you need to know which two acronyms determine which compliance regime you're building for. They're not the same thing.
PII vs PHI: The Definitions That Determine Your Compliance Regime
People throw PII and PHI around like they mean the same thing. They don't. And in the context of PHI and PII redaction in AI voice agents, that distinction changes everything: your compliance regime, your vendor contracts, your build requirements.
PII is any data that can identify a specific person. Name, phone number, email, SSN, card number, device ID. Governed by GDPR, CCPA, and whatever state privacy law applies to where your users are.
PHI is narrower. It's PII that relates to health status, healthcare treatment, or payment for care, AND is held by a HIPAA-covered entity or its business associates. That "and" is doing a lot of work.
This is why PII redaction rules can't be set by data type alone. They're set by context, by who holds the data, and what it was collected for.
For a full look at the security obligations that follow from this classification, see our guide on voice agent privacy and security.
Both are hard to protect in a web form. Voice agents are a different class of problem entirely.
Why Voice Agents Leak PII Differently Than Every Other Channel
Unlike AI chatbots, which receive PII through controlled input fields, voice agents get it as raw, unstructured speech. And that's what makes PII redaction so much harder here than in any other channel. No field validation. No character limits. A caller booking a dental appointment can volunteer their insurance ID, a child's SSN, and a home address in a single sentence, none of it prompted.
That's problem one. There are three more.
Real-time audio doesn't wait. With a form submission, you validate before writing to a database. With a voice stream, audio is already flowing to your ASR provider before you've finished processing the previous utterance. Across inbound and outbound voice flows, there's no natural pause-before-storage moment unless you build one in deliberately.
Third: callers volunteer data you never asked for. The agent asks for a date of birth. The caller gives the DOB, then their insurance member ID, then their mother's maiden name. All three land in your transcript and your LLM context without any prompting.
And then the vendor chain multiplies everything. Twilio logs the call metadata. Deepgram gets the audio stream. Your LLM provider gets the full transcript in context. Your monitoring tool logs the trace. At the WebRTC and SIP transport layers, call metadata is logged before any redaction system can run. One piece of PHI hits four vendor environments in under two seconds.
This is why PHI and PII redaction in AI voice agents needs control at each stage of that chain. PII redaction that only covers the transcript is theater, not compliance.
Each of those four vectors maps to a specific stage in your pipeline. The next section names exactly where the exposure sits.
The Seven Places PII and PHI Actually Surface in a Voice Pipeline

The transcript isn't the risk. It's one of seven places where sensitive caller data surfaces in a standard voice pipeline, and most deployments I've seen cover two of them, maybe three.
Walking through that table, the entries that actually get teams in trouble aren't the obvious ones. Telephony and transcription, teams think about those. The real problems show up in the observability layer.
Here's a real pattern from Hamming's analysis of 4M+ production voice calls: an engineer adds a raw LLM prompt to an OpenTelemetry span three months ago while debugging latency. Nobody removes it. The transcript viewer shows asterisks. The Datadog trace shows the full card number. This is "redaction theater": the UI looks compliant, the infrastructure isn't.
PII redaction that covers only the transcript protects about 15% of the actual exposure surface.
In healthcare voice deployments, function calls returning patient records or appointment history are the most common source of PHI entering the LLM context window unprompted. If your agent queries a voice AI knowledge base for clinical protocols or insurance SOPs, that API response carries structured PHI straight back through the pipeline. And agentic RAG systems that pull from policy documents or medical records introduce a document-level exposure risk at the tool output stage that almost nobody maps during the build.
So PHI and PII redaction in AI voice agents requires controls at all seven stages, not just the two that your users can see.
"The voice agent tells the caller it won't repeat their card number. The OpenTelemetry span stores it in six different ways." - Hamming, analysis of 4M+ production voice agent calls, 2025.
Knowing where the leak is gets you halfway. Each stage needs its own technique, and they're not interchangeable.
Redaction Techniques That Actually Hold at Each Stage
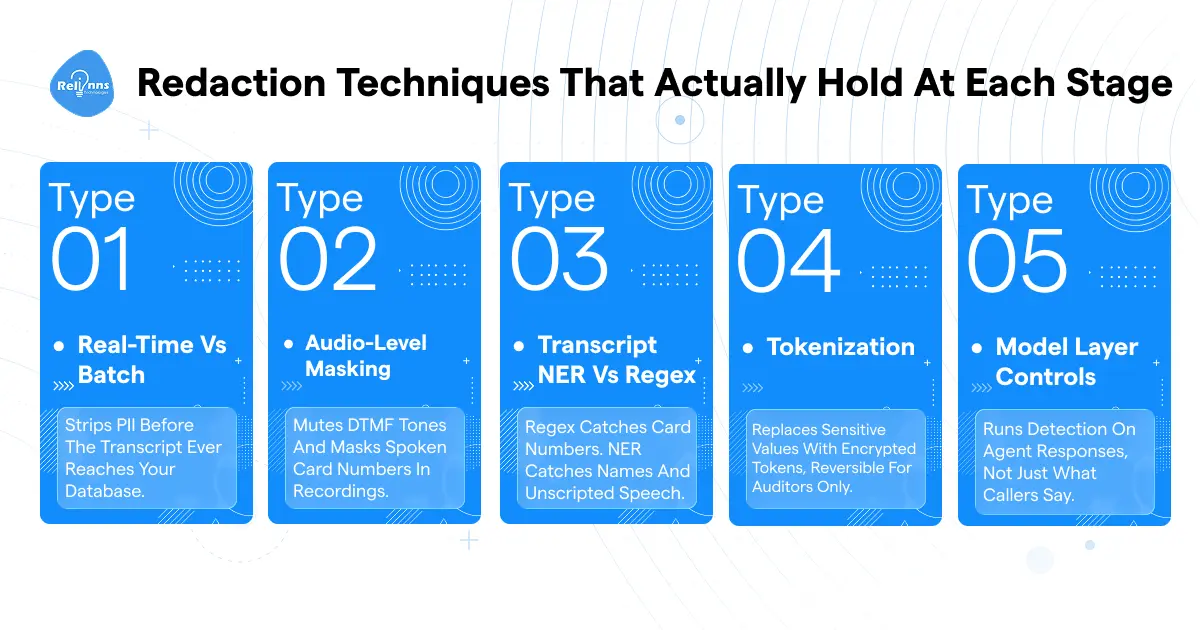
No single technique covers the full pipeline for PII redaction. Each stage demands its own approach. Use the wrong one in the wrong place, and you get either a compliance gap or a transcript so degraded it becomes useless for debugging.
Real-time vs Batch
Real-time for production. Batch as a verification layer only. For teams already managing voice agent latency at the infrastructure level, the 10-50ms cost of real-time redaction is manageable with buffered chunk processing.
Audio-level masking
Transcript redaction doesn't touch recordings. Two things to handle at the audio layer. Configure Twilio to suppress DTMF tones during IVR payment entry. PCI DSS requires it, and it's an architectural control, entirely separate from transcript work.
The HIPAA shortcut most teams don't know about: delete the original audio after extracting a redacted transcript. Stored recordings are HIPAA identifier #16, voice biometrics. Delete the audio, and that entire identifier exits your compliance scope.
Transcript NER vs Regex
This is where I see the most mistakes in production deployments.
Regex fails on voice. A caller saying "four, one, one, one" doesn't match a 16-digit card pattern. NER catches it. Production voice agents need both. For multilingual voice agents, NER accuracy also varies by language: English hits 94-96% F1, and lower-resource language models can drop well below that.
Tokenization
Two options. Irreversible replaces sensitive data with a label like [CREDIT_CARD_1], which is standard for transcript storage. Reversible tokenization encrypts the original value and stores a lookup token in a secure vault, used when compliance officers or auditors need to recover a specific value for investigation.
Model layer controls
Getting PHI and PII redaction in AI voice agents right means treating the LLM as a data path, not just a processing step. LLM selection for voice agents directly affects what data leaves your environment, which vendor agreements you need, and whether on-prem deployment is even viable for your compliance posture. Self-hosted ASR like Deepgram on-prem keeps audio within your environment. Cloud ASR requires a signed BAA for any HIPAA-covered entity.
And run your detection pipeline on agent outputs, not just caller inputs. An LLM that surfaces records through a tool called can echo PHI straight back in its own response without any prompting. How you structure voice AI prompting also controls how much raw conversation history the model receives per turn, which directly limits what PII redaction needs to catch at the model layer.
Transcribe first, then redact. The original unredacted transcript should never reach your database. If your pipeline stores first and runs a background redaction job, your compliance gap is exactly as wide as the time between those two events.
Techniques cover the how. Before you build, you need to know which regulatory frameworks apply, because each one sets a different bar for what "redacted" legally means.
The Compliance Frameworks Your Voice Agent Answers To
One voice agent can sit under four compliance frameworks simultaneously. Take a healthcare insurer in Dubai processing US-based claims: HIPAA applies because it's health data touching a covered entity, GDPR kicks in if any EU citizens are involved, UAE PDPL governs because processing happens on UAE soil, and PCI DSS applies the moment a caller reads out a card number for a premium payment. Four regimes, one call. This is exactly why PHI and PII redaction in AI voice agents can't be designed around the framework your legal team knows best.
Your redaction design has to satisfy the strictest framework you touch, not the most convenient one.
For a full breakdown of what it takes to build and operate a HIPAA-compliant voice agent, including BAA specifics and audit trail standards, that guide covers it in detail.
Insurance voice agents face the full PCI DSS requirement the moment a caller reads out a card number for a premium payment or claim. Ecommerce voice agents hit the same trigger during any order confirmation or payment update call. And logistics voice agents operating across the UK, UAE, and EU face a three-framework compliance requirement on the same call when the cargo involves a cross-border shipment.
One practical note on HIPAA for 2026: the updated Security Rule, published in 2024, remains in proposed form as of mid-2026. Build your PII redaction controls to the current rule in force, and track the Federal Register for updates to the timeline. Don't engineer for legislation that isn't enacted yet.
GDPR: 4% of global annual revenue. HIPAA: $1.5M per incident category per year. CCPA: $750 per consumer per incident. PCI DSS: $100K per month. These are the active enforcement figures your voice agent operates under right now, not theoretical maximums.
Frameworks tell you what you must achieve. The architecture section shows you how to build a system where compliance is structural rather than something you retrofit before an audit.
What a Redaction-Safe Voice Agent Pipeline Actually Looks Like
Most redaction failures aren't technique failures. They're placement failures. Redaction sits too late in the pipeline, and by the time it runs, the original data has already been written to two or three systems. Understanding the full AI voice stack is the prerequisite for knowing where each control actually belongs.
Here's how a properly sequenced pipeline looks, stage by stage.
Stage 1: Capture (Twilio/SIP).
Dual-channel recording separated at source. TLS 1.2+ transport. DTMF suppression active during any payment or authentication flow. Metadata scoped to the minimum required fields only.
Stage 2: ASR (Deepgram).
Audio streams to Deepgram under a signed BAA for HIPAA deployments, or self-hosted for full data isolation. 2-3 chunk boundary buffering before NER detection runs. Redaction executes before any transcript writing. Confidence threshold at 0.85 for production.
Stage 3: Voice synthesis (ElevenLabs / Retell AI).
Output sanitization runs on the agent's text response before it reaches ElevenLabs. This captures PHI that surfaces via a tool call and would otherwise be spoken back to the caller verbatim.
Stage 4: LLM context.
Redacted transcript passed to the model. Tool call responses from CRM, EHR, and claims APIs are sanitized before injection into context. Minimum necessary context per turn.
Stage 5: Recording vault.
Store dual-channel audio with masking at sensitive segments, or delete original audio after extracting a redacted transcript. Deletion removes voice biometrics from the scope, which matters because stored recordings qualify as HIPAA identifier #16.
Stage 6: Observability.
Custom OTel span processors scrub attributes before export. No raw LLM prompts in any trace, ever. Log filters strip PII from all application output.
Stage 7: Audit trail.
Log entity types, timestamp, detection version, and the vendor that processed the data. Not the values themselves. This is what you show in a compliance audit.
What stays in your environment versus what leaves:
- Your environment: recordings, transcripts, audit logs, PII vault
- Vendor environments: audio stream (Deepgram), text prompts (LLM provider), call metadata (Twilio)
- BAA or DPA required for: Deepgram, your LLM provider, any vendor receiving PHI from regulated subjects
Relinns builds on Retell AI, Deepgram, ElevenLabs, and Twilio. The architecture above is how we deploy for clients handling PHI and PII in AI voice agents across healthcare, insurance, and financial services, while simultaneously complying with HIPAA, PCI DSS, and GDPR. PII redaction is built at ingress. Not patched in after a compliance review.
If you're starting from scratch, the full walkthrough on building an AI voice agent covers the infrastructure decisions and the redaction controls described here. And this architecture needs to hold under production load. The guide covers the decisions that govern scaling AI voice agents without opening new compliance gaps.
Even well-designed architectures fail at predictable points. The next section covers the specific mistakes that show up in actual breach reports.
The Mistakes That Get Teams Fined and the One-Line Fix for Each
These aren't hypothetical risks. They're the patterns that show up in breach disclosures for teams that treated PHI and PII redaction in AI voice agents as a configuration task rather than an architecture decision.
Every mistake in that table is a PII redaction gap. In a regulated environment, any one of them is enough to trigger a finding.
The last one is the most underestimated. Platform-native PII redaction is marketed as a compliance feature. What it actually covers is the transcript viewer. OTel traces, debug logs, and analytics pipelines stay wide open, and that's where most actual breaches originate.
Regression testing your voice agent against synthetic PII datasets is how you validate the full pipeline before production. Not just the display layer.
And it's worth saying directly: AI voice agents vs. human agents carry fundamentally different compliance risk profiles. Human agents can be retrained after a policy change. A voice agent's exposure doesn't need a bad day to surface. It just needs a gap in the architecture.
The gap between a compliant voice agent and a non-compliant one isn't intent. It's whether the redaction controls are structural or added after the audit.
Ready to Build It Right?
Relinns is HIPAA compliant. We build AI voice agents for clients in healthcare, insurance, and financial services, where PHI and PII redaction in AI voice agents is required by vendor agreements and regulatory audits, not listed as features.
The architecture in this guide is how we handle PII redaction in production for clients operating under HIPAA, PCI DSS, GDPR, and UAE PDPL simultaneously.
Retrofitting compliance after launch costs more than building it in from the start. See how voice agent costs break down when compliance is part of the original build, not a later addition.
Compliance in voice AI is a custom AI development problem. There's no off-the-shelf configuration that covers your specific stack, your vendor chain, and your regulatory exposure simultaneously.
Book a technical consultation. We'll map your current pipeline against the seven exposure stages and show you exactly where the gaps are. Already running a voice agent in a regulated vertical and unsure if your current PII redaction holds up under HIPAA or GDPR scrutiny? Ask us for a compliance architecture review.



