

How to Build an AI Voice Agent in 2026: Architecture & Stack
Date
Jun 27, 26
Reading Time
10 Minutes
Category
AI Voice Agents
Share
The phone call never died. You stopped answering it.
88% of customers still reach for the phone when something goes wrong. Businesses pushed support to chat and email. The calls kept coming.
When you build an ai voice agent that handles them at scale, it takes more than a demo. This guide covers architecture decisions, stack selection, and production deployment.
The stack has matured. You no longer need ML engineers to build this. The components exist.
You'll learn how to build an AI voice agent, how the three architectures compare, how to keep latency under one second, and what separates a voice agent that ships from one that gets switched off.
How to Build an AI Voice Agent: Step-by-Step Process
Eight decisions, in order. Each one narrows the options for the next.
- Define the call workflow: Map which call types the agent owns, what actions it can take, and the exact conditions for human transfer.
- Choose your architecture: Cascaded pipeline, half-cascade, or native speech-to-speech. The choice sets your latency floor and cost ceiling.
- Select the telephony layer: Twilio, AWS Connect, or WebRTC based on channel type and geography.
- Add STT: Deepgram Nova-3 or AssemblyAI for real-time streaming. Configure custom vocabulary for domain-specific terms before go-live.
- Connect the LLM and tools: Set up function calling, define escalation logic, and link your CRM or booking system.
- Add TTS: Pick a voice, enable streaming, and target first-byte delivery under 200ms.
- Test latency and interruptions: Run scripted and adversarial scenarios. Target under one second end-to-end.
- Monitor after launch: Track completion rate, containment, CSAT, and average handle time from day one.
Why Businesses Are Building AI Voice Agents
Most phone automation is IVR. Press 1, press 2, follow the script. Step outside it and the call dies. A voice agent works differently. It listens, reads intent from natural speech, and responds without a menu. Callers get answers. Calls don't drop off.
This is why more businesses now want to build an AI voice agent instead of relying only on traditional phone support. Unlike IVR, Conversational AI Agents can manage real conversations, ask follow up questions, route complex cases, and complete repetitive call workflows at scale. And the numbers don't lie too;
97% of mobile users have used a voice assistant.
89% of customers prefer brands that offer voice AI support.
Businesses that deploy it report 20-30% lower operational costs.
The phone channel is not going anywhere, but the old way of staffing it is running out of road. From the clients we provided solutions for we observed that pressure shows up in five specific places where human teams cannot keep up at scale:
Repetitive inbound volume. In logistics alone, 50-70% of inbound calls are WISMO queries. The same question, thousands of times a day, answered by agents who could be doing something harder.
After-hours calls with no one to answer. Patients book appointments at midnight. Loan applicants call on Sundays. Customers don't time their questions around business hours.
No-show losses with no recovery system. Clinics lose 15-25% of appointments to no-shows. Without automated follow-up, that slot goes empty and the revenue disappears with it.
Manual outbound at scale. Renewal reminders, EMI follow-ups, delivery confirmations. Every call follows the same script. Hiring agents to read it is expensive and unnecessary.
Volume spikes that human teams cannot absorb. Ten agents handle ten calls. A voice agent handles thousands at the same time, with no queue and no hold music.
Now lets get into the nerdy but exciting details (if you are a tech enthusiast like me) of building your ai voice agent.
3 AI Voice Agent Architectures: Cascaded, Half-Cascade, and Speech-to-Speech
Before you build an AI voice agent, you need to choose the right technical foundation. The architecture decides how fast the agent responds, how much control your team has, how easily you can debug issues, and how predictable the cost becomes at scale.
Three production patterns dominate voice agent architecture today. Each one makes a different tradeoff between latency, control, and cost. Picking the wrong one can create problems that are expensive to fix later.
Architecture 1: The Cascaded Pipeline
This is the most widely used production architecture in 2026, and for good reason.
Three specialized models run in sequence, STT converts audio to text, The LLM processes that text and generates a response and TTS converts the response back to audio. Plain text moves between each component, and that simplicity is the point.
Realistic end-to-end latency sits between 500 and 800ms. That is not the fastest option, but it gives you something the other architectures cannot: full modularity. You can swap Deepgram for AssemblyAI, replace ChatGPT with Claude, or move from Cartesia to ElevenLabs without touching anything else in the system. Every component produces logs. Every layer can be measured, tuned, and replaced independently.
Most high-volume, telephony-based, compliance-sensitive deployments run on this architecture. Not because it is the most sophisticated, but because it is the most controllable.
How to Build a Voice Agent Using Cascaded Architecture
Each component runs on its own. Swap any one without touching the rest.
- Telephony stream: Connect via Twilio or AWS Connect. Route inbound audio to your STT layer over SIP or WebRTC.
- Streaming STT: Run Deepgram Nova-3 in streaming mode. Transcription starts before the caller finishes speaking.
- LLM orchestration: Pass the transcript to GPT-5 or Claude Sonnet with a prompt that defines scope, tone, and escalation conditions.
- Function calling: Connect your CRM, booking system, or database. The LLM calls these mid-conversation and waits for the result.
- Streaming TTS: Send LLM output to Cartesia or ElevenLabs. Audio starts playing before the full response finishes generating.
- Logging and replay: Capture transcripts and audio at every layer. Component-level logs pinpoint failures by layer.
- Human handoff: Define the exact intent signals and keywords that trigger a warm transfer to a live agent.
Architecture 2: The Half-Cascade
Audio goes directly into a multimodal model that hears it natively. Only the output side routes through a specialized TTS model.
That single change drops latency to 300-500ms, and it opens up something the cascaded pipeline cannot do. The model hears a caller who sounds frustrated. It catches rising intonation on a question. It picks up a mid-sentence language switch. No transcription step stands between the audio and the model's understanding. The output stays on a specialized TTS model, so you keep fine-grained control over voice quality on the other end.
ElevenLabs Agents and Google's Gemini Live both run on this pattern. It is the right call when how someone says something matters as much as what they say.
Architecture 3: Native Speech-to-Speech
One model. Audio in, audio out. No text intermediary, handoffs, no component boundaries.
Latency drops to 200-300ms. Below 300ms, conversation stops feeling like software, and that threshold matters for use cases where hesitation breaks trust.
The tradeoffs are real. On long calls, cost runs high because the model re-processes all prior conversation tokens on every turn. A call that looks like $0.30 per minute can reach $1.50 in practice. You also lose all component-level control. If something goes wrong, you cannot isolate which layer caused it, because there are no layers.
One more constraint worth knowing: PSTN phone calls run on 8kHz audio. That strips out much of what makes native audio understanding valuable and narrows the quality gap with cascaded pipelines considerably.
How to Choose between these 3 Architectures?
Start with the cascaded pipeline if your deployment involves telephony, compliance logging, or cost predictability. The modularity alone justifies it for most enterprise use cases.
Move to the half-cascade if audio understanding on the input side matters, callers switching languages, emotional tone detection, or anything where transcription loses signal you need.
Use speech-to-speech only if sub-300ms latency is a hard requirement and your call volumes keep unit economics manageable. It is the right architecture for a narrow set of use cases. For most deployments, the cascaded pipeline gets you further.
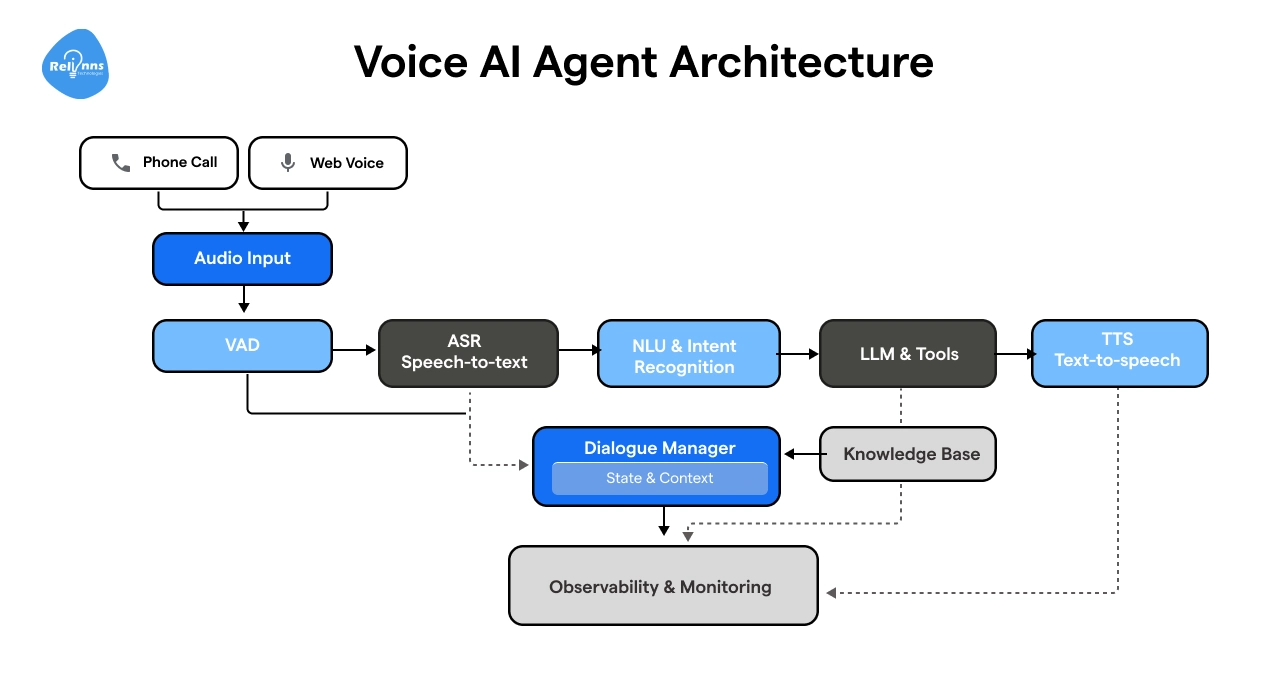
5 Important Layers to Build an AI Voice Agent
Whenever you build an ai voice agent, regardless of complexity, runs on the same core pipeline. Audio goes in, a response comes out, and what happens in between determines speed, accuracy, and how natural the conversation feels.
| Layer | Role | Common Tools | Enterprise Consideration |
|---|---|---|---|
| Telephony | Call routing | Twilio, AWS Connect, SIP | Region coverage, number portability |
| STT | Speech transcription | Deepgram, AssemblyAI, Whisper | Accents, noise, vocabulary |
| LLM | Reasoning and response | GPT, Claude, Gemini, Llama | Latency, compliance, tool use |
| TTS | Voice output | ElevenLabs, Cartesia, PlayHT | First-byte latency, brand voice |
| Orchestration | Turn-taking and routing | Retell AI, Vapi, LiveKit | Barge-in, handoff, monitoring |
The five components are:
1. Telephony Layer: The entry point. A caller dials a number, the telephony layer captures the audio and routes it into the pipeline. Twilio, AWS Connect, and WebRTC are the common options.
2. Speech-to-Text (STT): Converts the caller's audio into text. Background noise, accents, and domain-specific vocabulary all affect output quality, and accuracy problems here carry through every layer that follows.
3. LLM: The brain of the operation. It takes the transcribed text, reads intent, decides what to do, and generates a response. If the agent needs external data, an order status or account balance, it calls a tool here and waits for the result before responding.
4. Text-to-Speech (TTS): Converts the LLM's text response back into audio. Voice quality and response speed both live in this layer.
5. Integrations: The connectors to your actual systems: CRMs, booking platforms, databases, payment processors. Without these, the agent can talk but cannot act.
The full pipeline when you build an ai voice agent looks like this:
Caller → Telephony → STT → LLM → TTS → Telephony → Caller
Each handoff adds latency. Each component can fail independently. Knowing where each one sits is what separates a five-minute debug from a five-hour one.
Let's look at each layer in depth.
Layer 1: Speech-to-Text
STT converts spoken audio into text. Everything downstream works from that output, so errors here carry through the entire pipeline.
The model listens to an audio stream, breaks it into chunks, and predicts the most likely word sequence using acoustic patterns and language probability. Modern STT runs fast enough to transcribe word by word as the caller speaks.
What affects the accuracy of STT?
Four things degrade STT in production: background noise, strong accents, domain-specific vocabulary, and low-quality audio. PSTN compounds this further. The 8kHz audio ceiling strips out frequencies that help models distinguish similar-sounding words.
Tools used in STT
Deepgram Nova-3 is the default for real-time telephony. It handles noisy environments, multiple accents, and low-bitrate audio well. AssemblyAI Universal-Streaming is stronger on clean audio. OpenAI's gpt-4o-transcribe performs well but adds latency that hurts in a live call. Whisper is capable but built for batch, not streaming.
Streaming vs batch
Batch waits for the caller to finish before processing. Streaming transcribes as audio arrives. For voice agents, streaming is the only viable option.
Vocabulary gaps
Most STT models struggle with brand names, medical terms, and industry jargon out of the box. Custom vocabulary lists, pronunciations and domain-specific fine-tuning close that gap. If your agent operates in healthcare, logistics, or finance, budget time for this before go-live or just contact us to make sure everything is perfect and ready to deploy from day 1.
Layer 2: The LLM
The STT layer produces text. The LLM decides what to do with it.
It reads the transcript, identifies what the caller wants, determines the right action, and generates a response. On simple calls that means answering a question. On complex ones it means calling an external tool, waiting for the result, and building that data into a natural reply, all within the time it takes a human to pause between sentences.
Choosing a model for your agent
GPT-5 and Claude Sonnet are the most reliable LLM choices for voice agents in 2026. Both handle context well, follow instructions tightly, and produce responses short enough for spoken delivery. Gemini 3 Flash is worth considering when latency is the priority. Llama and Mistral work for teams that need on-premise deployment or tighter cost control.
Prompting for voice
Voice prompts have one constraint chat prompts don't: length. A voice agent that reads out a paragraph loses the caller. Responses need to be short and built for spoken delivery. Your system prompt should specify tone, response length, escalation conditions, and exact phrasing for situations where the agent has no answer.
Function calling
When a caller asks for their order status, the agent calls your order management system or CRM, waits for the result, then responds. This is what separates an agent that can talk from one that can act. One constraint: function calls block streaming. Design the conversation flow around that pause.
Memory
Session memory keeps context within a single call so the caller doesn't repeat themselves. Persistent memory carries information across calls. Most deployments start with session memory and add persistence once the core pipeline is stable.
Layer 3: Text-to-Speech
TTS is the last thing a caller hears. A response can be accurate, fast, and contextually right. If it sounds robotic, the caller disengages.
What makes a voice sound natural?
Three things separate a natural human-like voice from robotic TTS: prosody, pacing, and first-byte speed. Prosody is the rise and fall of speech that makes a sentence sound like a question or a statement. Pacing is knowing where to pause. Models trained on large volumes of human speech handle both well, and the gap between robotic and human-sounding audio has closed considerably since 2025.
The tools for TTS
Cartesia Sonic leads on latency, producing the first audio byte faster than most alternatives. ElevenLabs produces the most natural-sounding output and supports voice cloning from a short audio sample. OpenAI's gpt-4o-mini-tts is a reliable default for teams already in the OpenAI stack. PlayHT and Rime are worth testing for specific accent or regional tone requirements.
Voice cloning feature
Most platforms let you clone a voice from a short recording. For enterprise deployments, this means a consistent brand voice across every call. A hospital sounds calm and clinical. A QSR chain sounds fast and upbeat. Set this before go-live.
Streaming TTS
Streaming TTS sends audio before the full response finishes generating, so the caller hears the first word while the model is still producing the last sentence. The metric that matters is first-byte latency, not total generation time. For live call deployments, target sub-200ms.
Layer 4: Telephony and Channel Integration
The telephony layer is where the outside world connects to your pipeline. How audio gets from a caller to your STT model determines call quality, latency, and how much infrastructure you control.
How calls connect to your Agent?
Three protocols handle this. PSTN is the standard phone network but caps audio at 8kHz, which degrades every model downstream. SIP sits on top of PSTN for VoIP calls and gives you more control over routing. WebRTC runs over the internet at higher audio quality, making it the right choice for browser or app-based interactions. Most deployments use SIP for inbound calls and WebRTC for web surfaces.
Telephony Solution providers
Twilio is the default: broad geographic coverage, reliable SIP trunking, strong documentation, higher cost at volume. AWS Connect suits teams already on AWS infrastructure. Vonage works well for international deployments, particularly across Europe and the Middle East.
Orchestration platforms
Retell AI, Vapi, and LiveKit sit between your telephony provider and your STT/LLM/TTS stack. They handle real-time audio routing, turn management, interruption detection, and handoff logic. Retell AI is the most production-ready for phone deployments. Vapi offers more flexibility for custom pipelines. LiveKit is strongest for WebRTC use cases.
Inbound vs outbound flows
Inbound flows wait for a caller to connect, then run the pipeline reactively. Outbound flows dial a number, confirm identity, and execute a scripted workflow such as a payment reminder or appointment confirmation. Both flows use the same pipeline. The difference is who initiates the call and how the opening is structured.
How to Improve Latency in an AI Voice Agent
Latency is the gap between when a caller stops speaking and when the agent responds. Under 500ms feels natural. Above 1.5 seconds, callers assume the call has dropped.
Target under one second end-to-end.
Where does the latency comes from?
Every component adds time. STT streaming adds 50-150ms. LLM inference adds 200-500ms depending on model and prompt length. TTS first-byte generation adds 100-200ms. Network transit adds latency at each hop. A pipeline with average performance at every layer lands at 1.5 seconds before any optimisation. Function calls make it worse, pausing inference entirely until the tool returns, adding 300-800ms on top.
How to cut it out?
Streaming is the biggest lever. Run STT in streaming mode so transcription starts before the caller finishes speaking. Use streaming TTS so audio plays before the full response generates. These two changes cut perceived latency by roughly 40%.
Cache responses for high-frequency queries. If most callers ask the same three questions, pre-generate those responses and serve them instantly.
Deploy components in the same region. An STT model in US-East calling an LLM in EU-West adds 80-120ms of pure network latency on every turn.
For the lowest ceiling, native speech-to-speech brings end-to-end latency to 200-300ms. The cost tradeoffs are real, but the gain is significant where conversation pace matters.
Barge-in handling
Barge-in detection listens for caller audio while TTS plays, cuts the response mid-sentence, and reroutes immediately. Retell AI and Vapi both support it natively. Tune the audio threshold to reduce false triggers from background noise.
Deployment Options for Your AI Voice Agent
Where you deploy affects cost, compliance, latency, and infrastructure control. The decision matters more than most teams realise until they're already in production.
Cloud Deployment
Cloud is the default. AWS, Azure, and GCP offer managed services for every pipeline component, fast setup, automatic scaling, and no hardware to maintain. The tradeoff is data leaving your environment, which matters in regulated industries.
On-premise Deployment
On-premise keeps all audio, transcripts, and customer data inside your own infrastructure. For healthcare, financial platforms, or any deployment in a market with data residency laws, this is often a requirement. Open-source components like Whisper and self-hosted LLMs make it viable without rebuilding every layer.
Hybrid Deployment
Hybrid splits the pipeline by sensitivity. Telephony and STT run on-premise to keep raw audio contained. LLM inference runs on managed cloud. TTS runs wherever latency is lowest. This is common in enterprise deployments where compliance teams approve data handling layer by layer.
Compliances to take care of
HIPAA requires Business Associate Agreements with every vendor, encrypted audio storage, and access logging for US healthcare deployments. GDPR applies to any pipeline handling EU residents, with explicit consent disclosures for call recordings. UAE, Saudi Arabia, and Germany each impose data residency restrictions on where conversation data can be stored. Map your vendor stack against these before go-live.
Scaling Routine
Cloud deployments scale horizontally. On-premise needs capacity planning ahead of known peaks. Test at three to five times your expected peak volume before go-live.
Monitoring
Track these four things at all costs:
1. Call completion and transfer rates
2. Component-level latency across STT, LLM, and TTS
3. Failed tool calls
4. Unhandled intents,and conversation transcripts for replay.
A spike in transfer rate means conversation design has broken. Climbing LLM response time usually means the prompt has grown too long or a tool call is hanging. LangSmith covers LLM observability. Datadog or Grafana handle infrastructure metrics.
Testing and Evaluation of your voice agent
Most voice agent failures are predictable. They show up in testing if you test the right things.
- Start with scripted scenario testing across your 20-30 core call flows.
- Then run adversarial testing: interrupt the agent, give it incomplete information, ask outside its scope.
- The failures that matter are wrong answers delivered confidently, escalations that never fire, and tool calls that leave callers in silence.
- Tools like Hamming and Vapi's evaluation suite let you simulate hundreds of scenarios programmatically.
As we talked above also, only these four metrics matter: task completion rate, containment rate, CSAT, and average handle time. Track all four from day one. Before you go-live, test at three to five times expected peak volume. Components that hold at 10 concurrent calls often break at 100.
After launch, review transcripts weekly. Use them to refine prompts, tighten function definitions, and expand fallback handling. The agents that improve fastest have a structured review process behind them.
10 Hard-Earned Lessons for Developers Building Voice AI Agents
Most developers who build AI voice agents for the first time walk in with the same assumption: pick a good model, write a solid prompt, ship. Six weeks later they're debugging dropped calls, chasing latency spikes, and wondering why the agent confidently answers questions with information it fabricated.
10 Lessons about Building voice agents that teaches you things no documentation warns you about.
1. Transport layer beats model choice. Choosing UDP over WebSockets moves the needle more than which LLM you're running. Most models perform well with a solid prompt. Latency and infrastructure don't respond to prompting.
2. One agent, one job. When you need to handle multiple distinct tasks, spin up multiple agents. Make sure they can talk to each other. Rogue agents don't cooperate well with anyone.
3. Function calling blocks streaming. Function calling requires a full response before anything streams. That latency is real. Design your conversation flow around the pause, not against it.
4. Long context windows lie. Overstuffing a prompt is a bet you'll lose. The longer the context, the more the model hallucinates at the edges. Feed it what it needs.
5. RAG adds power and maintenance. RAG introduces a data pipeline you now own, update, and keep current. Weigh that overhead honestly before committing.
6. Live API tools beat static RAG for real-time data. If your agent needs current information, live API access outperforms any retrieval layer built on yesterday's data.
7. Tool execution needs a re-prompt. After a tool call fires, the model doesn't automatically receive the output. Update the conversation history and pass it back. Miss this and your agent responds to nothing.
8. Prompts are architecture, not copy. Test them like code. Iterate on them like code. They are the foundational logic of your agent.
9. Voice output and transcripts will diverge. What the caller heard and what your logs captured won't always match. Don't let QA rely on transcript accuracy alone.
10. Voice infrastructure is not text infrastructure. Scaling patterns you've solved for text don't carry over. Voice has different latency profiles, connection behaviors, and failure modes. Start fresh.
What Does Building an AI Voice Agent Actually Cost?
Building in-house runs $25,000 at the low end for a basic proof of concept, $150,000 to $300,000 for an enterprise-grade system, and three to twelve months of engineering time before anything goes live. That's before compliance work, ongoing maintenance, and the 15-28% annual operational overhead that follows every production deployment.
The team alone, AI engineers, backend developers, DevOps, QA, costs $150,000 or more per year. And that's a team spending their time on infrastructure, not on your core business.
Minimum Architecture Needed for a Real-Time Voice Agent
Six components. Build these before anything else.
- Telephony or WebRTC input: Twilio or WebRTC routes caller audio into your pipeline.
- Streaming STT: Deepgram Nova-3 transcribes audio in real time as the caller speaks.
- LLM with short prompts: GPT-5 or Claude Sonnet with a system prompt under 500 tokens. Longer prompts raise latency.
- Streaming TTS: Cartesia or ElevenLabs starts playing audio before the full response finishes generating.
- Logging: Capture transcripts and audio at every layer from day one.
- Fallback and handoff: Define a transfer condition for anything the agent cannot resolve.
One Step Before You Build
Voice agents can cut your inbound call volume, recover no-shows, and run outbound campaigns without adding headcount. But the gap between a working demo and a production deployment that holds under real call volume is where most builds stall.
Relinns has delivered and maintains 34 AI voice agent projects from 2026 to the time of writing this blog alone all across healthcare, logistics, insurance, and ecommerce.
We have worked with every major tool in the stack: Retell AI, Vapi, ElevenLabs, Deepgram, Twilio, and more. We know where each one breaks and how to build around it.
If you want to know whether a voice agent fits your workflow, book a call. We will scope your use case, recommend the right architecture, and tell you what it costs to go live.



