

How to Scale AI Voice Agents to Millions of Calls Without Breaking?
Date
Jun 09, 26
Reading Time
9 Minutes
Category
AI Voice Agents
Share

Most teams can build a voice agent. Very few can scale AI voice agents past 10,000 concurrent calls without something breaking.
The AI models themselves are fine. Speech recognition, LLMs, and voice synthesis have all gotten good. What breaks is everything around them. Telephony infrastructure, streaming pipelines, concurrency management, latency under load. These are what take down production systems.
And the gap between demo and production is bigger than people expect. Voice is unforgiving in ways that chat isn't. A two-second delay in chat is annoying. In a phone call, it sounds like a dead line. Sub-second response times aren't nice-to-have but they're the baseline your callers expect.
This blog is about what it takes to scale AI voice agents in production. Thousands of concurrent calls. Unpredictable spikes. Real compliance requirements. We'll cover the architecture decisions, failure modes nobody warns you about, and what scalable voice AI looks like when it's built right.
New to AI voice Agent space? Start with what AI voice agents are.
What Actually Lives Inside an AI Voice Agent?
Before you think about how to scale AI voice agents, you need to understand what's running during every call. It's not one system. It's five systems working in sequence, and each one can slow you down or break entirely.
Most engineers treat it like "AI on a phone call." That framing gets you into trouble. Building scalable voice AI means understanding this pipeline cold before you touch infrastructure.
The Five-Layer Pipeline
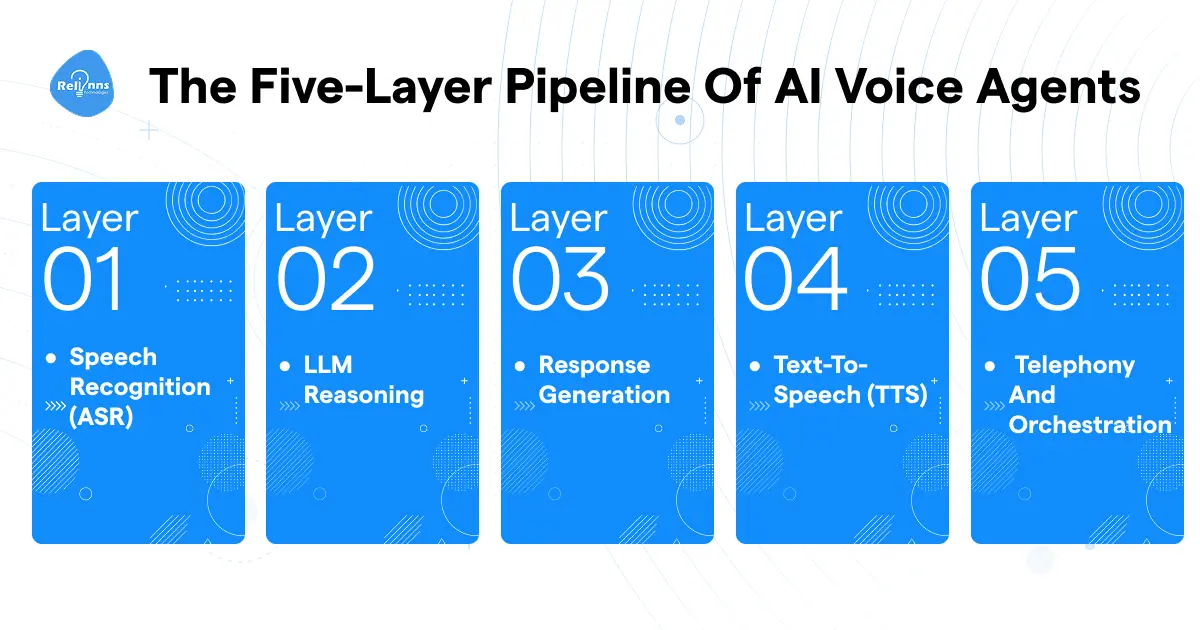
1. Speech Recognition (ASR) converts incoming audio to text in real time. Bad transcription poisons every decision downstream.
2. LLM Reasoning takes that text, identifies what the caller wants, and decides what the agent says next. Context from earlier in the call lives here. What are AI agents cover how this reasoning layer works across different architectures.
3. Response Generation turns the LLM output into words the caller hears. Tone, clarity, and pacing all happen here.
4. Text-to-Speech (TTS) converts generated text back into audio. Getting that audio to sound natural takes more tuning than most teams expect.
5. Telephony and Orchestration sits underneath everything. Call routing, audio streaming, conversation state, handoffs. The WebRTC vs SIP choice at this layer has real effects on latency.
The Event Flow: Audio in → ASR → LLM → response → TTS → audio out.
Latency stacks at every arrow in that chain. When you scale AI voice agents to high call volumes, that accumulated delay is the first thing that breaks the caller experience.
Why Scaling Voice Breaks What Scaling Chat Doesnt?
Chat is forgiving. Voice isn't.
A 2-3 second response time in a text conversation is invisible. In a phone call, that same delay sounds like a dropped line. Your caller either hangs up or says "hello?" twice. At high call volumes, that pattern destroys your CSAT scores fast.
And it's not just latency. There are four compounding problems that hit when you start to scale AI voice agents past demo traffic, and they tend to show up together.
1. Concurrency means thousands of live pipelines, not requests.
Each active call runs its own full stack: ASR, LLM, TTS, telephony. At 5,000 concurrent calls, you're running 5,000 real-time processes in parallel. Infrastructure that works fine at 50 calls starts degrading at 500.
2. Latency budgets are tight per component.
ASR needs to finish in under 300ms. LLM inference under 500ms. TTS under 200ms. You have roughly a 1-second window end-to-end. Miss any component and callers hear it.How to cut voice agent latency goes deep on where teams lose time.
3. The cost model runs on duration, not messages.
This surprises most teams. A 5-minute call generates far more compute than 5 chat exchanges. LLM and TTS costs accrue by the second. At scale,that math changes your unit economics.
4. Traffic spikes are a different problem.
A billing cycle, a product outage, a service disruption. Call volume can jump 10x in under 10 minutes. Scalable voice AI infrastructure has to absorb those spikes without queue buildup or response slowdown. Web traffic ramps over hours. Calls arrive all at once.
When you scale AI voice agents to production, these four problems don't queue up politely. They compound.
The Architecture That Holds Up Under Real Traffic
Most voice agent architectures work fine at 50 concurrent calls. Add a zero and things start creaking. Add another and the decisions you made early are either holding the system up or pulling it apart.
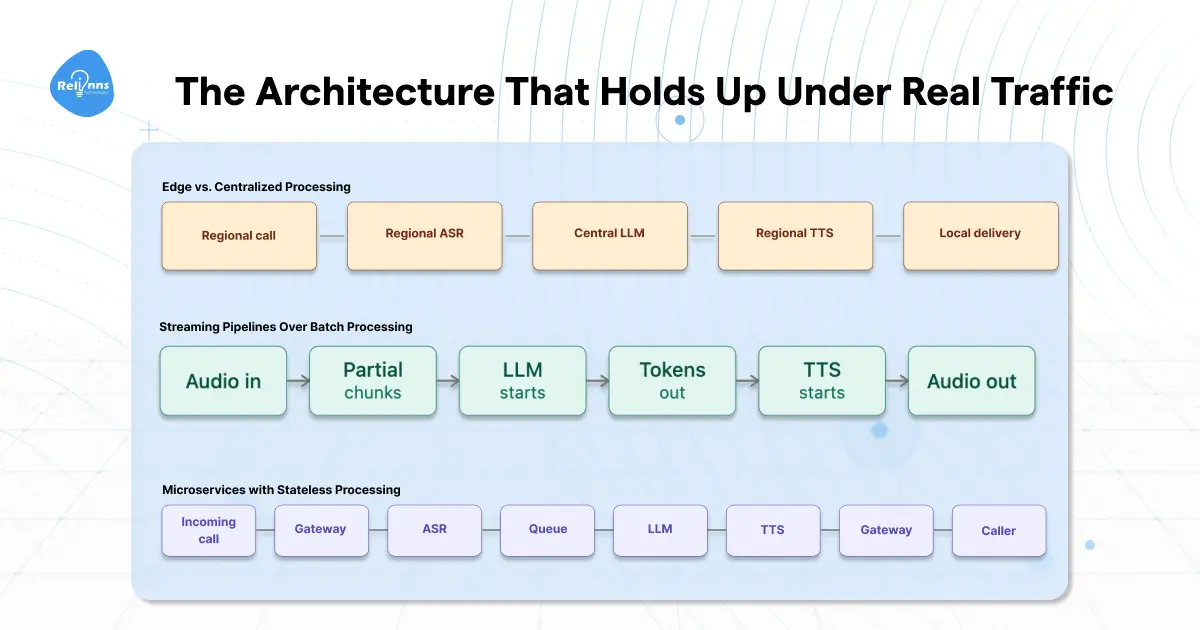
The teams that scale AI voice agents without drama share one thing: they don't treat the pipeline as one system. They break it into independent layers, stream everything they can, and put compute close to callers.
Three architectural decisions drive most of that.
Microservices with Stateless Processing
The most common mistake: one service handling ASR, reasoning, TTS, and telephony together. When LLM inference slows during a spike, everything backs up and you can't isolate the problem.
Break each layer into its own service.
ASR scales on its own. TTS scales on its own. If one component becomes the bottleneck, you scale that one without touching the rest.
The harder part is state. Voice calls are stateful. Store conversation context in Redis. Any node in your cluster can pick up the session, so if one fails mid-call, another reads from cache and continues. The caller notices nothing.
How to build an AI voice agent walks through the decisions behind each layer.
Streaming Pipelines Over Batch Processing
Batch processing is the default and it's slow. Most systems wait for the caller to stop speaking, then transcribe, then call the LLM, then wait for the full response, then hand off to TTS. Every "then" is added latency.
Stream every step that can be streamed. Start transcribing while the caller is still speaking. Feed partial transcriptions to the LLM as they arrive. Stream tokens to TTS as they generate. The TTS system starts synthesizing sentence one while the LLM is still writing sentence three.
This cuts perceived latency by 40-60% without changing a single underlying model.
Edge vs. Centralized Processing
A caller in Dubai hitting infrastructure in Virginia adds 150-200ms before a byte of processing occurs. That's geographic latency you can't remove from a centralized setup.
The pattern that works: ASR and TTS at the edge, close to callers. LLM inference at centralized GPU clusters where compute is cheaper. Heavy reasoning at the center, audio processing at the edge.
For teams that need to scale AI voice agents across multiple regions, centralized architecture becomes the first thing that limits you. Building scalable voice AI with this hybrid keeps response times tight regardless of where your callers are.
How to Cut Latency Without Cutting Quality?
Latency work isn't about swapping in a faster model. It's about removing dead time at every step. Most scalable voice AI deployments get this wrong in the same ways.
The biggest win is streaming ASR.
Most systems wait for the caller to stop speaking before transcribing. Flip that. Start transcribing mid-speech. By the time the caller finishes, the LLM is already processing a partial transcript. That one change cuts 200-300ms on its own.
Pair it with token streaming to TTS. Don't wait for the full LLM response before handing off. Stream tokens as they generate. TTS starts synthesizing sentence one while the LLM is still on sentence three.
The model you pick affects how well this pipeline streams. Done right, streaming ASR and token streaming together cut perceived response time by 40-60% with no model change.
Silence detection calibration is something most teams skip. Cut off at 0.3s and your agent interrupts callers mid-sentence. Wait 1.5s and there's dead air after every turn. Tune this per use case. A healthcare intake flow needs more patience than an order status bot.
On model routing: use a lightweight model for intent classification first. Pull in the heavier model only when the reasoning demands it. Most calls don't. The teams that scale AI voice agents well route by complexity, not by default.
Check how the top AI voice platforms handle this at the infrastructure level.
When you scale AI voice agents without fixing latency at each layer, faster hardware won't help. The bottlenecks are structural, not computational.
Running Thousands of Concurrent Calls Without Degrading
Vertical scaling hits a ceiling fast. To scale AI voice agents past 1,000 concurrent calls, horizontal is the only viable path. More CPU on one server helps until it doesn't, and when that server fails, everything fails with it.
Containorize each service, deploy behind a load balancer, and autoscale on real signal.
For voice systems, the three most reliable triggers are queue depth, p95 latency, and active call count. CPU alone is a lagging signal. By the time it spikes, calls are already degrading.
Session management is where most horizontal setups break down. Each call has live state: what's been said, what context the LLM holds, where the caller is in the flow. Store that in Redis, not in the node handling the call.
Any node in the cluster can pick up the session if another fails. Skip Redis and keep state in-memory on the node, and the first node restart ends that conversation mid-call. It's a common shortcut that becomes a production incident.
Traffic patterns change how you size autoscaling. Inbound vs outbound voice AI behaves differently at volume. Inbound is unpredictable. Outbound campaigns are schedulable, so you can size ahead of time. Set tighter autoscale thresholds for inbound, plan capacity for outbound.
For global traffic, multi-region failover isn't optional. Route callers to the nearest healthy region. Scalable voice AI infrastructure scales in minutes where human agent teams take weeks of hiring to catch up. When you scale AI voice agents across regions, that elasticity is the whole point.
What Breaks First, and How to Design Around It?
Production voice systems don't fail spectacularly. They fail quietly. Garbled audio for two seconds. An agent talking over a caller. A session dropping mid-flow with nothing to recover it. Most teams that want to scale AI voice agents discover these failure modes from customer complaints, not from testing.
- Network jitter and packet loss hit first.
Unlike HTTP requests, audio streams can't retry silently. A 200ms packet loss event in a text API call is invisible. In a voice call, it's garbled audio or dead silence, and callers read that as system failure.
Jitter buffers at the telephony layer absorb short-burst instability. Set audio quality thresholds and prompt the caller to confirm or offer a callback when quality drops.
- Barge-in handling gets bolted on after launch by most teams.
That's the wrong order. Callers interrupt, and an agent that keeps talking over them after the first interruption loses trust fast.
Build interruption detection from day one. When the caller speaks mid-response, the system pauses, processes the new input, and adjusts. How you prompt the agent directly affects how gracefully this works.
- Long calls are a context problem nobody plans for.
A 7-minute troubleshooting call generates 4,000+ tokens of conversation history. That pushes you past model context windows or inflates LLM cost per call. Implement context compression: summarize earlier turns, keep only the most relevant context active. How you structure the knowledge base matters as much as the compression strategy for knowledge-heavy calls.
Call drops happen. Every session needs to be recoverable. Preserve state to cache on disconnect, detect drops fast, trigger callbacks where the use case warrants it.
And test your ASR on noisy audio before launch. Production callers call from cars, open offices, and construction sites.
Scalable voice AI has to handle those conditions. If you only tested on clean recordings, your real-world word error rate will be a surprise. When you scale AI voice agents without this prep, you find out from callers, not benchmarks.
That's an honest limitation of most early deployments.
Observability, Testing, and Compliance at Scale
The teams that scale AI voice agents well share one habit: observability set up before they need it. Not after the first production incident.
Track five metrics from day one:
- End-to-end response latency at p50, p95, and p99
- Word error rate from ASR
- Call success rate
- Escalation rate to humans
- Active concurrent call count.
Alert on p95 thresholds, not averages. A latency spike is often invisible in the mean until callers are already hanging up.
Load test before go-live. Simulate peak concurrent volume before real traffic hits it. Most teams skip this step and find their breaking point live. That's an expensive lesson.
Synthetic call simulation is worth the setup time. Generate artificial conversations with varied accents, background noise, pacing, and emotional tone.
This surface edge cases manual QA misses consistently. How AI voice agents hold up under real customer service conditions is a useful frame for what production traffic looks like vs. what you tested for.
On compliance: every voice call carries PII.
Encrypt audio in transit and at rest. Redact PII in transcripts before they hit logging or analytics layers. Don't store raw audio longer than your policy requires.
For regulated industries, HIPAA-compliant voice agent infrastructure covers the specific requirements in detail. Access control, audit logs, data retention, breach notification. Build these in before go-live. Retrofitting compliance after launch costs more and takes longer than doing it right the first time.
Keep audit logs on every model interaction. When you scale AI voice agents into regulated verticals, that audit trail is non-negotiable. Scalable voice AI infrastructure treats compliance as a first-class build requirement, not a final checklist item.
Final Word
Production voice failures get blamed on the model. The model holds up. The infrastructure around it doesn't.
The teams that scale AI voice agents well get there through infrastructure, not intelligence. Streaming pipelines. Session state in Redis. Compliance built before go-live. Monitoring that catches latency creep before callers notice.
That's what scalable voice AI looks like when it's working.
Relinns builds voice agent systems designed for production from day one. Architecture, load testing, compliance, and deployment are all part of the engagement. Whether you're looking at AI voice agents for healthcare or insurance automation, the infrastructure bar is higher than most demos suggest.
Ready to scale AI voice agents past the prototype phase?



