

What Is Agentic RAG? Concepts, Types, and System Architecture
Date
May 25, 26
Reading Time
18 Minutes
Category
AI Agents
Share
Most enterprise AI deployments hit the same wall: the system handles simple questions fine and falls apart the moment a query needs more than one retrieval step. Agentic RAG is what fixes that. Let's start from the ground up.
What Is Agentic RAG?
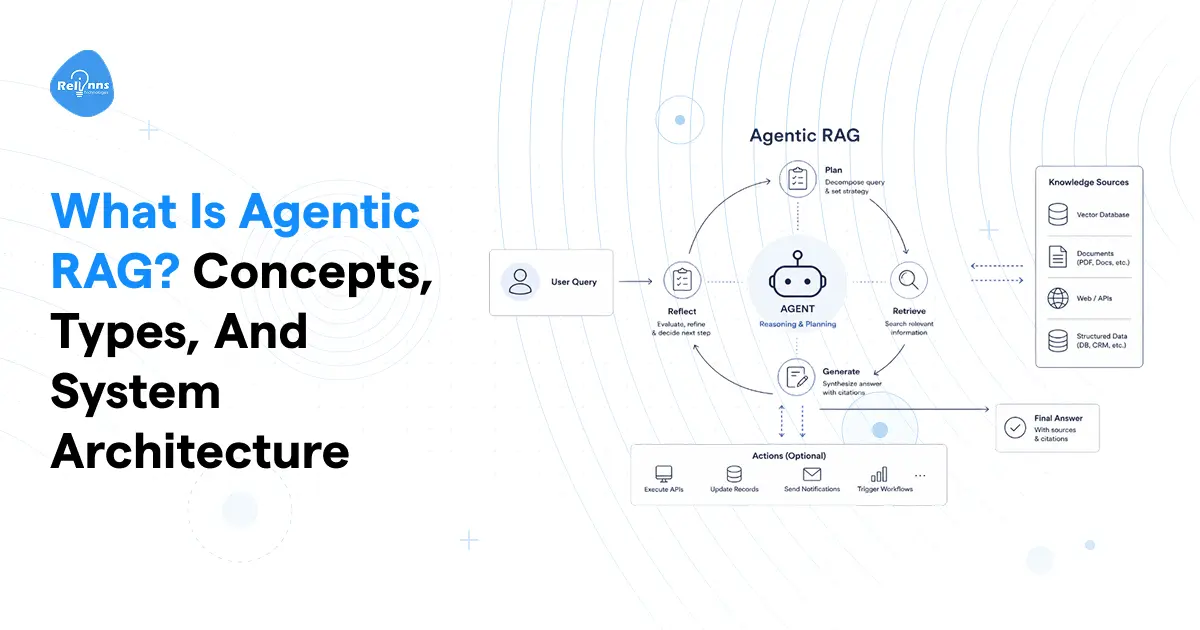
Agentic RAG is a RAG pipeline where AI agents control retrieval. Instead of fetching context once and hoping it's enough, a RAG agent reasons about what to retrieve, picks the right tool, checks what comes back, and retries if the result is weak. The key difference is that retrieval becomes a loop, not a single shot.
This article covers the fundamentals of RAG, where the standard approach breaks down, how agentic RAG works step by step, the different agent types, the architecture options, and where it's being used in production.
What Is Retrieval-Augmented Generation (RAG)?
RAG connects a large language model to an external knowledge base at the moment a query comes in. Not during training. At inference time, when the question is actually being asked.
The system has two parts. First, a retrieval layer: an embedding model paired with a vector database that holds your documents. Second, a generative layer: the LLM that produces the final answer.
Your query gets converted into a vector, the database finds the most similar chunks of content, and those chunks get passed to the LLM as context. The LLM doesn't guess. It reads what you gave it and responds based on that.
Teams adopted RAG for three reasons. It cuts hallucinations because the model works from retrieved facts, not memory. It doesn't need fine-tuning every time your data changes. And it keeps answers current because the knowledge base updates independently of the model.
For a lot of use cases like chatbots, RAG is enough. But not for all usecases.
Why Traditional RAG Falls Short
The retrieve-once-then-generate approach works until your queries get complicated. And enterprise queries get complicated fast.
Multi-step queries break it immediately. Ask a standard RAG system "compare the termination clauses in our 2023 contracts with our 2024 contracts" and watch it struggle. That question needs two separate retrievals, a comparison step, and some reasoning about the differences.
A one-shot RAG pipeline pulls context for whichever part of the query it latches onto first and generates an incomplete answer. The system doesn't know it failed. It just responds with whatever it found.
Then there's the recovery problem. If the first retrieval returns weak context, traditional RAG has no way to adapt. It can't recognize that what it fetched was insufficient. It can't try a different query, reformulate, or go look somewhere else.
The quality of your output is entirely determined by that one retrieval step. Get it wrong and the LLM confidently generates a response built on bad context.
And the third issue is scope. A standard RAG pipeline connects to one knowledge source. That's it. No web search, no SQL database, no CRM, no live API. So when a user asks something that needs current pricing data alongside internal policy documents, the system can only answer half the question. The other half gets fabricated or ignored.
These aren't edge cases. They're the norm in any enterprise deployment where queries reflect real business complexity. That's exactly the gap a RAG agent is built to close.
Types of RAG Agents
Not all agents in an agentic RAG system do the same job. Each type plays a specific role in the pipeline, and knowing the difference matters when you're deciding what to build.

Routing Agents
The routing agent is the first one in the chain. It decides where to send a query before any retrieval happens. Ask it something about internal HR policy, it points to your document store. Ask it for today's currency exchange rate, it calls a web search API.
Simple role, but it's what stops every query from hitting the same single source and returning irrelevant results. A RAG agent that routes well is the difference between a useful system and an expensive search bar.
Query Planning Agents
These are the task managers. When a complex query comes in, the query planning agent breaks it into ordered sub-tasks and dispatches each one to the right downstream agent. Each sub-task gets handled separately, and the planning agent pulls the results back together into one coherent answer.
This is AI orchestration in practice: one agent managing others. It's what makes agentic RAG actually useful for enterprise-grade queries that span multiple data sources or require sequential reasoning steps.
ReAct Agents
ReAct stands for Reasoning and Action. The loop goes: Thought, Action, Observation, repeat. The agent reasons about what to do next, takes an action (usually a tool call or retrieval step), observes what came back, and uses that to inform the next thought.
It maintains state across steps using short-term memory, so earlier results shape later decisions. The honest limitation here is that each loop adds latency. On complex queries, you might be waiting through four or five cycles before the agent produces an answer.
Plan-and-Execute Agents
Think of this as ReAct with better planning discipline. The agent maps the full workflow upfront before executing a single step, rather than deciding what to do next after each observation.
Once the plan is set, it runs without calling back to the primary agent at each step. That cuts token cost, reduces latency, and tends to produce higher task completion rates because the agent isn't improvising mid-execution. For long, multi-step workflows, this is the architecture worth building toward in an agentic RAG system.
How Agentic RAG Works
At its core, agentic RAG runs a planning and retrieval loop rather than a straight line from query to answer. Here's what that loop actually looks like step by step.
1. Query reception and planning
The primary RAG agent receives the query and assesses it before doing anything else. Simple query, simple plan. Complex multi-part query, the agent maps out the full sequence of steps it needs to take before retrieval begins.
2. Contextual understanding
Before fetching anything, the agent checks memory. Short-term memory covers the current conversation. Long-term memory holds past interactions and cached results. This step is what stops the agent from retrieving the same context it already has or ignoring relevant history.
3. Tool selection and retrieval strategy
For each step in the plan, the agent picks the right tool. Vector search for semantic document retrieval, a web API for live data, SQL for structured records, a document API for specific files. The tool choice happens per step, not once for the whole query.
4. Iterative retrieval and action
This is where the ReAct loop runs: Thought, Action, Observation, repeat. The agent executes a retrieval step, observes what came back, and decides whether it's sufficient. If the context is weak or incomplete, it reformulates and retries. It doesn't push bad input to the LLM and hope for the best.
5. Synthesis
Once the agent is satisfied with what it's collected, it combines all retrieved context with the original prompt into one complete input.
6. Final response generation
The LLM generates the answer from that assembled context. Grounded, multi-source, and built on retrieval the agent actually validated rather than whatever happened to surface first.
The honest caveat: each loop through steps 4 and 5 adds latency. On a straightforward query an agentic RAG system is slower than vanilla RAG. That tradeoff is worth it when the query is genuinely complex. It's not worth it when a single retrieval step would have worked fine.
How Do AI Agents Enhance RAG?
Think of vanilla RAG as a librarian who goes to one shelf, grabs whatever looks relevant, and hands it to you. Useful, but limited.
A RAG agent is more like a researcher. It reads your question, figures out what it actually needs to find, and decides which sources are worth checking. If the first source returns something weak, it goes looking elsewhere. It can cross-reference, verify, and pull from five different places before giving you an answer.
The agent doesn't just retrieve. It takes responsibility for whether what it retrieved is actually good enough.
What Does an Agentic RAG Architecture Look Like?
The architecture scales from a single routing agent handling a handful of tools all the way up to hierarchical multi-agent systems coordinating dozens of specialized retrievers. Here's what each level looks like in practice.
Single-Agent Agentic RAG (Router)
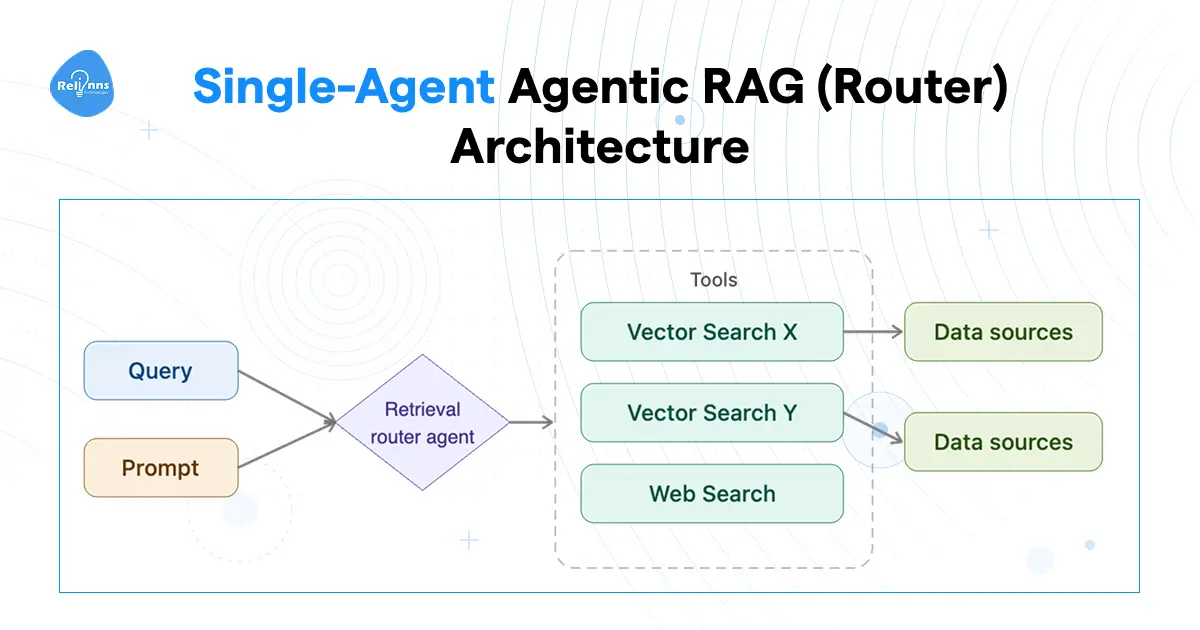
The simplest version. One RAG agent, two or more knowledge sources, and a decision to make at every query.
The agent reads the question and picks where to look. Internal policy document? Goes to the vector store. Live stock price? Goes to a web API. Recent customer email? Goes to the email account. The agent's only job at this level is routing, and it does that one job before any retrieval happens.
The single-agent setup is the right starting point for most teams. One agent, a small set of tools, and a clean routing decision at every query. If your use case is well-defined and your data sources are limited to two or three, this is all you need.
Multi-Agent Agentic RAG Systems
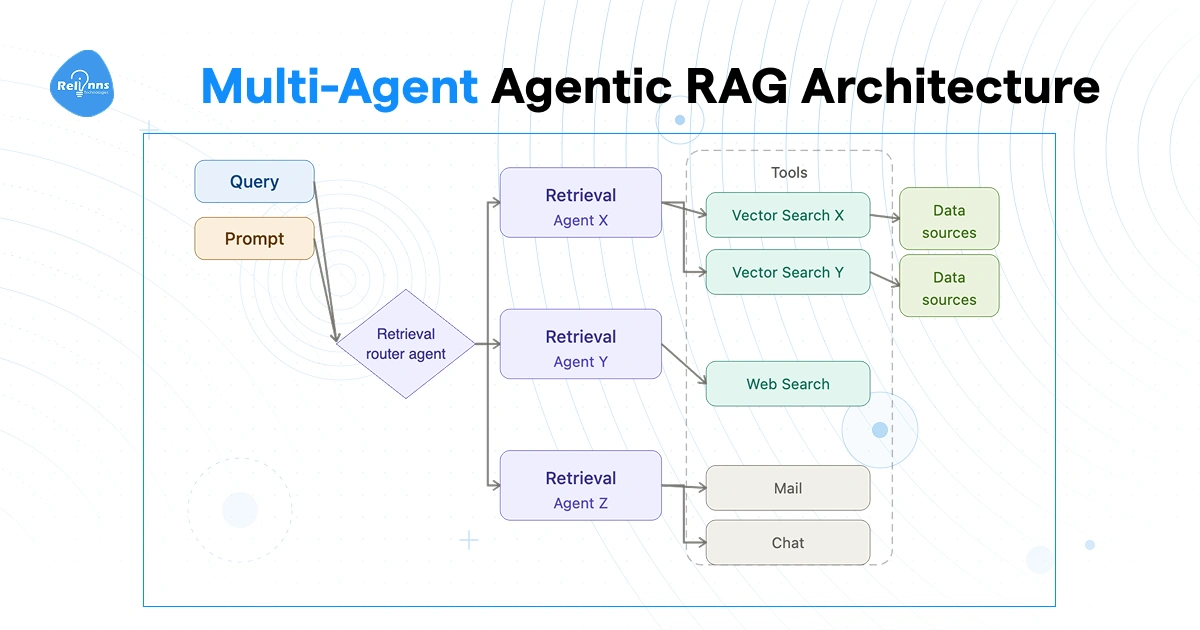
One agent hits its limits fast when queries need to pull from genuinely different domains at the same time. Multi-agent agentic RAG solves this with specialization. A master RAG agent coordinates a set of sub-agents, each owning a specific domain or data type: one handles internal documents, one covers email and Slack, one runs web searches.
The master agent doesn't do retrieval itself. It dispatches, then synthesizes. Sub-agents run their retrievals in parallel, which cuts total query time on complex requests. The master pulls all responses together and passes the combined context to the LLM.
Best for research-type queries, competitive intelligence, or anything where a single question legitimately needs data from internal systems, external sources, and live web content at the same time.
Hierarchical Agentic RAG Systems
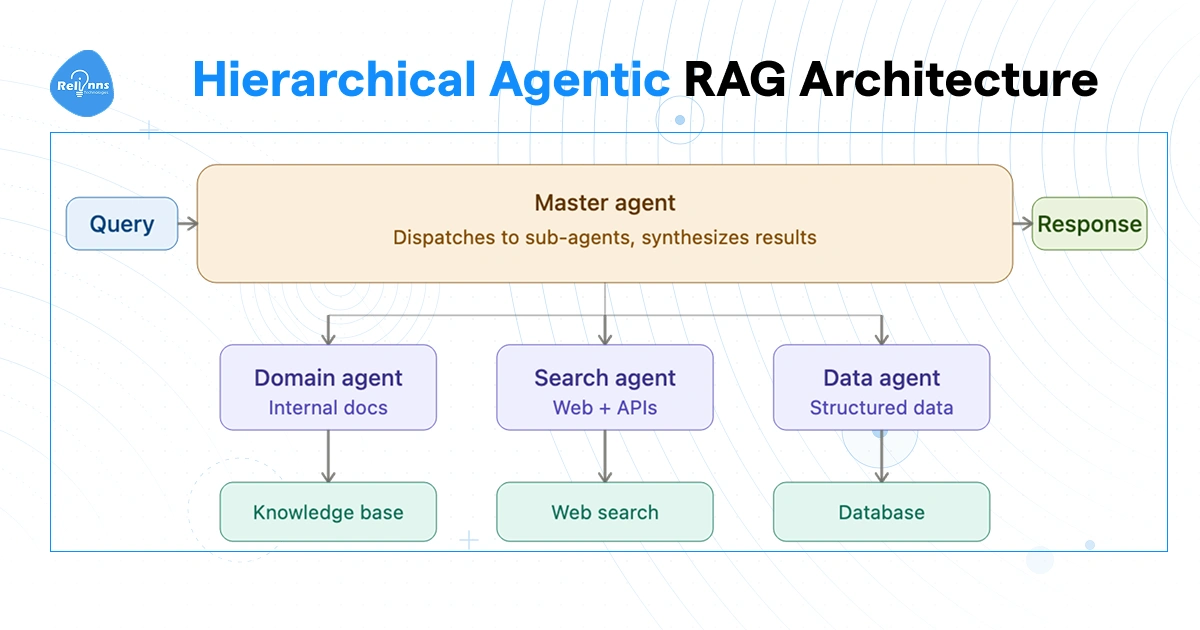
The hierarchical setup adds a supervision layer above the standard multi-agent approach. A master agent sits at the top and doesn't retrieve anything. Its only job is to assess the incoming query, decide which sub-agents to activate, and combine what comes back.
When a query lands, the master breaks it into sub-tasks and dispatches each one to a specialized tier-2 agent. Each sub-agent runs its own retrieval tools. Results bubble back up. The master synthesizes and responds.
Each tier only knows its own job. The master orchestrates. Sub-agents retrieve. A RAG agent failure at the retrieval level gets caught at the orchestration level before it corrupts the final answer. That's the whole point of the hierarchy.
Where this earns its added complexity: financial analysis pulling from regulatory filings, market data, and internal reports at the same time; compliance checks spanning multiple jurisdictions; anything where a flat multi-agent setup would produce conflicting or incomplete results without someone managing the pieces.
Adaptive Agentic RAG
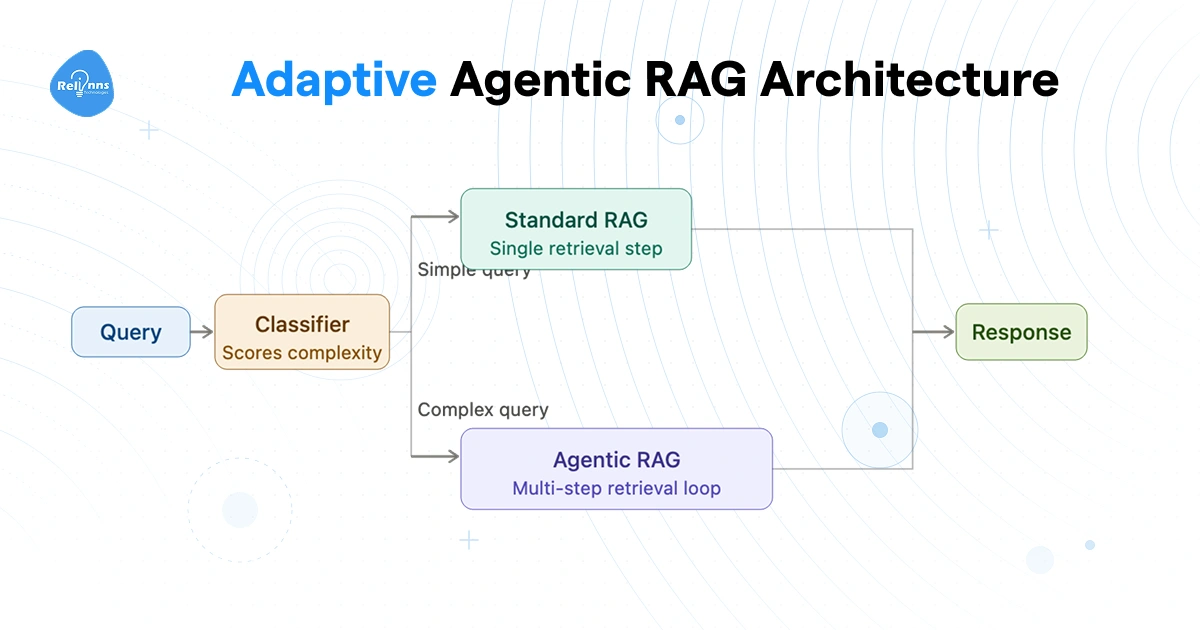
Most enterprise query volumes follow a predictable split. A large share of questions are simple and factual. A smaller slice genuinely needs multi-step agentic reasoning. Running everything through a full agentic RAG pipeline to handle that smaller slice wastes money and adds latency to queries that didn't need it.
Adaptive agentic RAG puts a classifier at the front. A smaller, faster model scores each incoming query for complexity before any retrieval happens. Simple query routes straight to a lightweight single-retrieval path. Complex query triggers the full RAG agent loop with multi-step planning.
Fast on the easy stuff. Thorough on the hard stuff. Neither path pays the cost of the other.
This is the architecture worth reaching for on high-volume deployments: customer support, internal Q&A, any context where query complexity varies widely across users. The classifier adds a small upfront cost per query, but the savings from not pushing "what's our cancellation policy" through a five-step planning loop add up fast at scale.
The honest caveat: classifiers misfire. A query that looks simple can require complex reasoning, and vice versa. Building solid evaluation data for your classifier matters as much as the pipeline it gates. Skip that step and you'll spend weeks debugging why a simple question triggered a five-step retrieval loop.
Knowledge Retrieval: The SQL vs Vector Database Decision
Most teams building agentic RAG systems default to vector databases without stopping to ask whether their data actually needs semantic retrieval. That assumption shows up early (usually in a tutorial) and then calcifies into architecture. For teams sitting on structured, relational data, that default adds real engineering overhead for a capability they don't need. This section is about when vector RAG earns that overhead and when SQL gets you to the right answer faster with less work.
The Default Assumption Problem
Vector RAG became the standard starting point because early RAG demos used it and most tutorials are built around it. The assumption stuck. But for any team working with structured data that already has a schema, starting with vectors means adding chunking, embedding, and tuning on top of a problem that a SQL query would solve in one step.
Understanding the Complexity Tax of Vector RAG
A RAG agent built on vectors requires three engineering layers that a SQL-based approach doesn't. Each one adds build time, tuning cycles, and its own failure modes.
Chunking Overhead
Documents have to be split into chunks before they're indexed, and where you draw those chunk boundaries directly shapes what the retrieval step returns.
Too small and chunks lose context. A policy clause split mid-sentence returns an incomplete fragment, not an answer. Too large and chunks dilute relevance scores, which means the retrieval step surfaces a 2,000-token block when the answer lives in 40 words buried inside it.
Overlapping strategies help with context loss but increase index size and retrieval cost, which means you're now paying more to fix a problem that chunking created.
Some concrete examples of where this breaks in practice:
- A hospital SOP split at 500 tokens may cut a dosage instruction across two chunks. Neither chunk returns cleanly because neither contains the complete instruction.
- An insurance policy chunked by paragraph loses the cross-reference between the exclusion clause and the definition section. The retrieval step returns one without the other.
- A warehouse inbound SOP chunked without overlap returns step 3 without step 2 because the query matched step 3's language. The floor team gets an incomplete procedure.
Retrieval Engineering
Keyword search alone misses semantic matches. Vector search alone misses exact term matches. Hybrid search combines both, but it requires configuration and weight tuning to actually work. Then reranking runs a second scoring pass over initial results to reorder by relevance, which adds latency and another variable to tune.
The result is a continuous optimization cycle: adjust chunk size, change overlap percentage, retune hybrid weights, rerun evals, repeat. This isn't a one-time setup cost. It's an ongoing maintenance commitment that your team signs up for the moment you ship a vector RAG system to production.
Integration Fragility
Poor chunking and weak retrieval feed low-quality context to the LLM. The LLM then generates confident-sounding responses built on bad inputs. The system doesn't know it failed. It just responds.
What makes this worse: standard LLM evaluations test output quality, not retrieval quality. You can score well on response coherence while the retrieval step has been returning the wrong documents for weeks.
A real example of how this surfaces: a logistics 3PL deploys a RAG agent over their SLA documentation. Two clients share overlapping terminology in their contracts. The retrieval step surfaces the wrong contract version for a query. The agent generates a response citing the wrong SLA tier. Nobody catches it until a client disputes a quarterly report. By that point, the error has been in production for weeks and the team has to audit every response the agent generated against those contract terms.
That's not a hallucination problem. It's a retrieval problem. And it's invisible until something breaks downstream.
The SQL Alternative: Structured Simplicity
For data that already has a schema or can be given one, a text-to-SQL agent workflow removes chunking, embedding, and reranking entirely. The engineering overhead just disappears.
Core Concept
The agent receives a natural language query and converts it to SQL against a structured database. There's no semantic guesswork involved. The query either returns the right row or it doesn't. Deterministic retrieval: the same question returns the same result every time.
That's a meaningful property in enterprise systems. A RAG agent built on vectors might return slightly different results across runs depending on embedding drift or retrieval scoring. A SQL-based agent doesn't drift.
This approach works well for transactional data, customer records, order histories, product catalogues, and FAQs where answers are discrete. If the answer is a number, a status, a date, or a named value, SQL finds it faster and more reliably than a vector search will.
Implementation Pathway
Not everything starts structured. PDFs, contracts, and manuals can be transformed into structured tables using tools like LlamaParse before loading into a queryable database. It's an upfront investment, but you do it once and the retrieval layer becomes straightforward.
Once structured, the text-to-SQL agent plugs into the broader agentic RAG workflow as one retrieval tool among others. The routing agent sends factual queries to SQL and semantic queries to the vector store. You only build the hybrid architecture where both are genuinely needed, not as the default starting point.
I've seen teams spend three months tuning a vector pipeline for data that had a clean relational structure the whole time. Starting with SQL and adding vector retrieval only where semantic understanding is required cuts that problem in half.
The Strategic Approach
Start with SQL. Add vectors when SQL breaks. Don't build both until you know you need both.
1. Start Simple, Add Complexity When Needed
If your data has a schema or can be given one in under a day, build the SQL path first. Validate that it answers the majority of your queries before adding anything else. Most teams discover that 60-70% of their query volume is factual and structured. SQL handles it cleanly. The vector layer only needs to cover the remainder, and you'll know exactly where that boundary sits because you measured it instead of guessing.
2. Hybrid Is Not Always Better
Hybrid retrieval sounds like the safe choice. It isn't. Combining SQL and vectors from day one doubles the surface area for failures and complicates every routing decision in the pipeline. Teams that skip the validation step and build hybrid upfront spend weeks debugging retrieval logic before a single user query gets answered correctly. Premature hybrid architecture is one of the most common reasons agentic RAG projects stall before they ship.
Quick Decision Framework
- Data has a clear schema: start with SQL
- Data is unstructured and queries need semantic understanding: use vectors
- Data is mixed or you're unsure: build SQL first, measure coverage, add vectors where SQL falls short
With the retrieval layer decided, the broader question is how agentic RAG pipelines compare to the vanilla RAG systems most teams are already running.
When Each Approach Wins
The decision comes down to what kind of question the data needs to answer.
| Dimension | SQL Databases | Vector Databases |
| Best for | Structured, relational data | Unstructured, semantic content |
| Complexity | Low: standard SQL queries | High: chunking, embeddings, tuning |
| Setup time | Fast: transform and query | Slow: experimentation required |
| Accuracy | High for factual queries | Better for conceptual similarity |
| Use cases | Customer data, transactions, FAQs | Knowledge bases, legal docs, research |
The table makes it look like a clean either/or, but most production agentic RAG systems end up using both. The mistake isn't choosing one over the other. The mistake is defaulting to vectors before you've checked whether your data actually needs them.
Start with SQL. Measure what percentage of your query volume it covers. Add vectors for the queries that genuinely require semantic understanding. That sequence is slower to design up front and much faster to ship, debug, and maintain than building a full vector pipeline on day one and discovering three months later that 70% of your queries were asking for rows, not concepts.
Traditional RAG vs. Agentic RAG
Both approaches solve the same core problem: grounding LLM responses in external knowledge. Where they differ is in how much intelligence sits between the query and the retrieval step. Traditional RAG is a pipeline. Agentic RAG is a decision-making loop. Neither is universally better. The right choice depends on what your queries actually look like in production.
| Dimension | Traditional RAG | Agentic RAG |
| Data access | Single knowledge source, one retrieval step | Multiple sources, tool use across APIs and databases |
| Process flow | Linear: retrieve once, then generate | Iterative: retrieve, evaluate, re-retrieve if needed |
| Task approach | Responds directly to the query as given | Breaks complex queries into sub-tasks, plans before retrieving |
| Adaptability | No recovery from weak retrieval | Self-corrects: reformulates queries, retries with different tools |
| Cost and speed | Lower token cost, faster response time | Higher token cost, more latency per query |
Is Agentic RAG Better Than Traditional RAG?
Depends entirely on the task.
A RAG agent earns its cost on multi-source queries, complex document processing, self-correcting pipelines, and workflows where a wrong answer has real downstream consequences. If your users are asking questions that require pulling from three data sources and reasoning across them, traditional RAG can't do that job.
But traditional RAG is the right choice for high-volume simple Q&A, latency-sensitive applications, and anywhere budget is tight. A customer support bot answering 50,000 "what's my order status" queries per day doesn't need an agentic loop. It needs fast, accurate, cheap retrieval.
The tradeoffs with agentic RAG are real and worth naming directly:
- Each reasoning step adds latency. On complex queries, users wait longer.
- Token cost per query is higher. At scale, that compounds fast.
- Agents fail on ambiguous tasks. Without clear failure handling, they can loop or produce confident nonsense.
- Hallucinations are reduced, not eliminated. Better retrieval lowers the risk but doesn't remove it.
Build agentic RAG where the complexity of the task justifies the cost. Don't build it because it sounds more impressive.
Why Are Enterprises Adopting Agentic RAG?
Vanilla RAG got enterprises past the hallucination problem. Agentic RAG gets them past the complexity problem. Lets look into benefits and Limitations now.

Benefits of Agentic RAG
The case for agentic RAG in enterprise deployments isn't theoretical. The numbers are specific.
1. Multi-source synthesis
Lets a single RAG agent pull from internal documents, live APIs, and structured databases in one query. The answer your team gets reflects the full picture, not whichever single source the system happened to check first.
2. Workflow automation goes deeper than Q&A.
Compliance checks, risk reports, and document reviews that previously required a human to pull sources and synthesize findings can run end to end through an agentic pipeline. The human reviews the output, not the process.
3. Accuracy improves meaningfully.
Error and hallucination rates in agentic RAG systems run under 10%, compared to over 20% in standard baseline systems. That gap matters in any context where a wrong answer has legal, financial, or operational consequences.
4. Research time drops.
Published benchmarks show a 63% reduction in manual research time when agentic RAG handles document retrieval and synthesis tasks. That's not a small efficiency gain. It's the difference between a team of five doing the work of three and doing the work of eight.
And the system scales across functions without rebuilding it. The same agentic RAG architecture that handles legal contract review can handle sales research, operations reporting, and customer support escalations. One system, multiple business functions.
Limitations of Agentic RAG
The benefits are real. So are the costs.
1. Each reasoning step adds latency.
A five-step agentic loop takes longer than a single retrieval. On latency-sensitive applications, that's a problem you need to plan for.
2. Token cost scales up fast.
Every LLM call in the agent loop costs tokens. On high query volumes, the cost difference between a traditional RAG pipeline and an agentic one is significant enough to show up in your infrastructure budget.
3. Agents fail.
In multi-agent setups especially, agents can get stuck in loops, fail to complete tasks cleanly, or collaborate poorly when the orchestration logic isn't tight. These failures don't always surface obviously. Sometimes the system produces an answer that looks correct and isn't.
4. Hallucinations
They are reduced, not eliminated. Better retrieval lowers the risk. It doesn't remove it.
And the system itself is more complex. More moving parts means more surface area for failures, more things to monitor, and more specialized knowledge required to debug when something breaks at 2am. If your team can't maintain what you build, the accuracy gains don't matter.
Use Cases of Agentic RAG
The industries where agentic RAG delivers the most value share a common profile: high document volume, multi-source data, and workflows where a wrong answer or a missed step has real consequences.
Top Use Cases for Agentic RAG in Healthcare
- Clinical knowledge assistants: A RAG agent queries SOPs, clinical guidelines, and drug databases in real time to answer physician queries across a multi-specialty hospital network. No switching between systems, no manual search.
- Pre-authorisation automation: The agent retrieves policy documents, patient history, and payer guidelines together and assembles a complete pre-auth pack. The manual back-and-forth between clinical staff and the TPA disappears.
- Post-consultation follow-up: Agent checks the care plan, pulls relevant patient history, and sends personalised follow-up instructions directly via WhatsApp. No human coordinator needed in the loop.
- Diagnostic lab report status: Agent queries the LIS, retrieves result status, and delivers it to the patient through voice agents or chat. The patient gets an answer without a human agent touching the query.
Top Use Cases for Agentic RAG in Ecommerce
- WISMO resolution: Agent pulls live shipment data from the logistics API and order data from the OMS, then generates a precise status update. No human agent needed, no ticket opened.
- Cart abandonment recovery: Agent queries browsing history, current inventory, and active promotion rules to generate a recovery message that's actually relevant to what the customer was looking at.
- B2B reorder automation: Agent monitors purchase history, checks live stock levels via API, and triggers reorder reminders at the right moment in the buying cycle. The buyer doesn't have to think about it.
- Seller onboarding for marketplaces: A RAG agent retrieves onboarding SOPs, checks submitted documents against requirements, and routes exceptions to the right internal team. Onboarding time drops without adding headcount.
Top Use Cases for Agentic RAG in Insurance
- Policy renewal follow-up: Agent retrieves expiry data, customer communication history, and renewal offer documents, then runs the outbound call. No human agent required for the standard renewal conversation.
- Claims status queries: Agent pulls the claim file, retrieves current status from the claims processor API, and delivers an accurate update to the policyholder. The call centre handles escalations, not status checks.
- Pre-authorisation coordination: Agent retrieves the hospitalisation request, patient policy details, and payer guidelines together, then assembles and submits the pre-auth automatically. The process that used to take days runs in minutes.
- FNOL handling: Agent gathers incident details from the customer, retrieves the relevant policy terms, and initiates the claim file in the system. First Notice of Loss becomes a structured intake, not a phone call.
Top Use Cases for Agentic RAG in Logistics
- Shipment tracking and NDR handling: Agent retrieves live tracking data, delivery attempt history, and customer contact preferences to resolve failed deliveries without escalating to a support agent. Failed delivery rate drops, re-attempt cost drops with it.
- Warehouse SOP copilot: Agent answers floor staff queries by retrieving the right SOP document on demand. During high-turnover periods, this cuts retraining time without requiring a supervisor to be available.
- 3PL client SLA reporting: Agent pulls shipment data across all client accounts, retrieves SLA terms per contract, and generates the report. The ops team that used to spend hours building these reports by hand gets that time back.
- Driver onboarding and compliance: Agent retrieves document requirements, checks submitted files against them, and flags expiries before they become violations.
How to Implement Agentic RAG
There are two ways to build an agentic RAG system: wire it yourself using function calling, or use a framework to handle the scaffolding. The right choice depends on how much control you need versus how fast you need to ship.
Option 1: Language Model Function Calling
You define the retrieval functions (vector search, web search, API calls), pass tool schemas to the LLM via the tools parameter, and write a loop that routes between the LLM and tool execution. That's the core of it.
This works with OpenAI, Anthropic Claude, Cohere Command-R, and open-source models through Ollama (Llama 3.2 and others). Choose this path if your team wants direct control over every step in the pipeline and has the engineering capacity to maintain it.
Option 2: Agent Frameworks
Frameworks handle the routing, memory, and orchestration logic so you don't build it from scratch:
- LangChain / LangGraph: pre-built tools, LCEL for chain composition, LangGraph for stateful multi-agent workflows
- LlamaIndex: QueryEngineTool templates built specifically for RAG retrieval patterns
- CrewAI: multi-agent systems with shared tool access across agents
- BotPenguin: no-code/low-code deployment of RAG agent workflows across WhatsApp, website, Instagram, and 10+ channels. Built for teams that need to deploy agentic conversational experiences without building the underlying infrastructure. BotPenguin already powers agentic RAG-backed chatbots for enterprises across healthcare, ecommerce, insurance, and logistics.
- AutoGen / Swarm: multi-agent orchestration frameworks; Swarm is built and maintained by OpenAI
Bottom Line
Agentic RAG isn't a drop-in upgrade to your existing pipeline. It's a different architecture with a different cost structure, different failure modes, and a significantly higher ceiling on what your AI system can actually do.
If your queries are simple and your data is clean, vanilla RAG handles the job fine. But if you're dealing with multi-step workflows, document-heavy processes, or queries that need to pull from more than one source to give a useful answer, a standard pipeline will keep disappointing you no matter how much you tune it.
The architecture is mature enough to build on. The frameworks are solid. The use cases across healthcare, insurance, logistics, and ecommerce are proven in production, not just in demos.
Start with the simplest version that solves your actual problem. Single-agent router, SQL-first retrieval, one or two tools. Validate it works. Then add complexity where the data and query volume justify it.
If you're evaluating where to start or need a team that's already shipped agentic RAG systems in your industry, Relinns builds exactly this. From standalone RAG agents to full multi-agent enterprise deployments, across the tech stack your team is already running.



