

Multimodal LLMs Explained: Vision Language Models and Beyond
Date
Mar 19, 26
Reading Time
10 Minutes
Category
Generative AI
Share
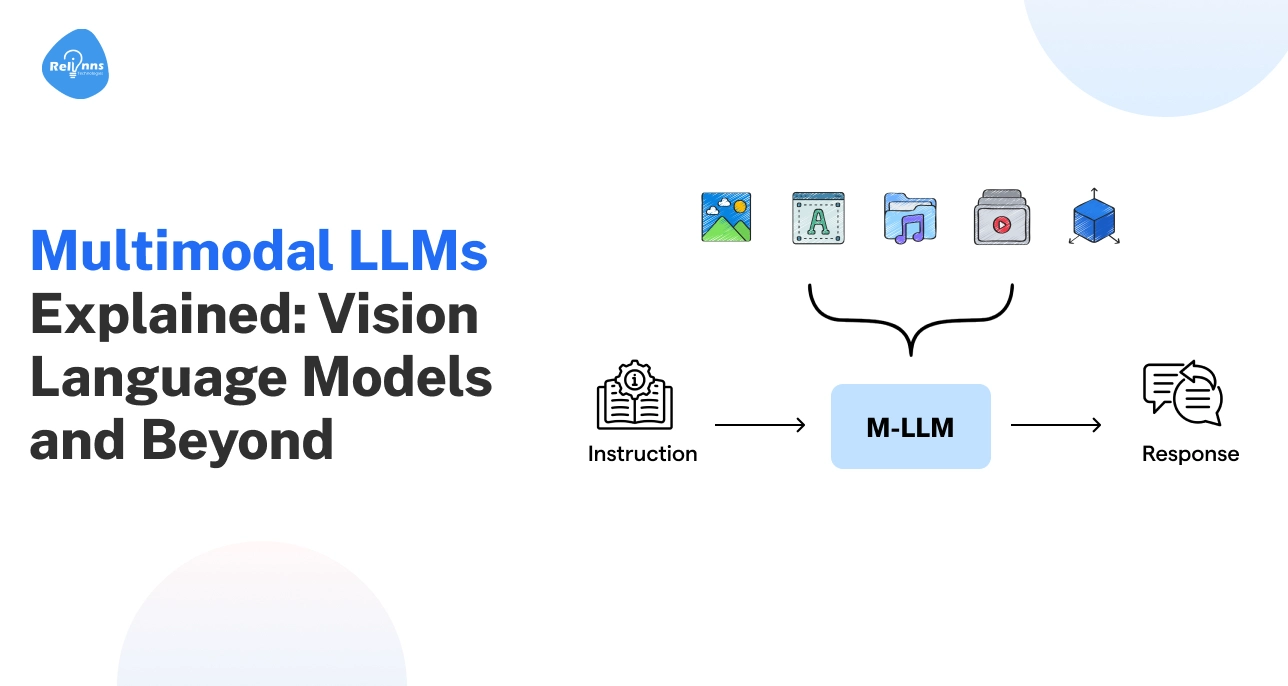
AI is finally learning to see, hear, and understand the world at once.
For years, systems processed text, images, and videos separately, limiting how much they could truly understand. Imagine asking an AI to describe a photo, summarize dialogue from a video, and explain related text in a single response.
However, multimodal large language models (multimodal LLMs) are changing that.
They combine language reasoning with visual and audio understanding, translating different data types into a shared representation. This allows them to analyze complex inputs and generate meaningful responses.
In this guide, you’ll learn what multimodal LLMs are, how they work, how they differ from vision-language and image-text models, and why they are becoming central to modern AI systems.
What is a Multimodal LLM? Explanation & Overview
Multimodal LLMs can process text, images, videos, and audio together.
Traditionally, a large language model would handle only text, limiting its understanding of richer data. Multimodal LLMs, on the other hand, understand context across formats, making them smarter and more versatile than traditional language models.
These models, such as GPT-4V, are part of broader multimodal AI systems, connecting different types of data for better insights.
Definition of Multimodal Large Language Models
A multimodal large language model (LLM) is an AI system designed to handle and reason over multiple types of data at once.
It can read text, interpret images, listen to audio, and even analyze video, combining all inputs to generate meaningful output.
For instance, a multimodal LLM can look at a product image, read its description, and summarize customer reviews to give a full recommendation.
Why LLMs are Evolving Beyond Text
Traditional LLMs only process text, which doesn’t give the full context in real-world data. Some of the reasons why multimodal LLMs are emerging include:
- Richer Context: Combining visuals, audio, and text gives a deeper understanding.
- Improved Reasoning: Connections across formats help detect patterns humans might miss.
- Faster Decision-Making: Multiple inputs can be processed simultaneously.
- Broader Applications: Enables AI to assist in healthcare, retail, finance, and more across a wide range of real-world use cases
Companies are increasingly building custom multimodal systems for tasks like visual search, document analysis, and intelligent assistants. To unlock the full benefits, many teams partner with AI development experts like Relinns Technologies that help them design and implement tailored multimodal LLM solutions.
In the real world, AI often needs to go beyond just reading or describing data; it has to understand the type of input it’s dealing with and how different modalities interact.
That’s where multimodal LLMs differ from other AI architectures like vision-language models or image-text models.
In the next section, we’ll explore these differences and see how each model type works.
Multimodal LLM vs Vision Language Models vs Image-Text Models
Many AI systems already combine images and text, but they do not all work the same way. Some focus only on linking visuals with language, while others extend large language models to reason across many data types.
The table below highlights the key differences between image-text models, vision-language models, and multimodal LLMs.
| Model Type | Supported Modalities | Architecture Focus | Common Use Cases | Real-world Model Examples |
| Image-Text Models | Image + text | These models map images and text into a shared embedding space, allowing the system to measure similarity between visual and language representations. (“Does this photo match this caption?") | Image captioning, visual search, product tagging | CLIP, ALIGN |
| Vision-Language Models (VLMs) | Image + text (sometimes video) | These models jointly process visual and language inputs to understand images and generate text responses about visual content. ("Describe what is happening in this photo.") | Visual question answering, document understanding, image reasoning | LLaVA, BLIP-2 |
| Multimodal LLMs | Text, image, audio, & video | These models extend large language models with modality encoders that translate different inputs into a shared representation, enabling reasoning across multiple data types. ("Watch this video, listen to the audio, and write a poem about the mood.") | AI assistants, multimodal analysis, complex decision systems | GPT-4V, Gemini 1.5 Pro, Claude 3.5 Sonnet |
While image-text and vision-language models connected visuals with language, multimodal LLMs extend this idea by combining modality encoders with a powerful language model to reason across different data types.
How Multimodal LLMs Work: Behind the Architecture
Multimodal LLMs combine several AI components to interpret different types of data. The architecture typically follows four key stages.
Modality Encoders for Images, Audio, and Video
Each input type is first converted into structured representations using specialized encoders.
- Vision encoders process images and video frames into visual embeddings.
- Audio encoders convert speech or sound signals into numerical representations.
These encoders transform raw inputs into embeddings that the model can process.
Alignment and Projection Layers
Encoded inputs must be aligned so they can interact with the language model.
- Alignment layers map visual and audio embeddings to a shared representation with text.
- Projection layers convert modality embeddings into the LLM’s token space.
This step ensures different inputs can be interpreted together.
Multimodal Fusion Mechanisms
The model then combines information from different modalities.
- Fusion layers merge signals from text, images, audio, and video.
- The model learns relationships between inputs across modalities.
This process builds a unified contextual understanding.
LLM Backbone for Reasoning and Generation
Finally, the language model interprets the combined information and produces outputs.
- The LLM analyzes the fused multimodal representation.
- It performs reasoning across the combined inputs.
The LLM thus generates answers, summaries, explanations, or creative responses.
Core Capabilities of Multimodal Language Models
Multimodal language models have quickly become powerful tools for interpreting complex, real-world data that appears in multiple formats.
Here’s a breakdown of their core capabilities:
- Visual Understanding and Image Reasoning: The model can analyze images, identify objects, understand scenes, and answer questions about visual content. It can also explain relationships between elements in a picture.
- Document, Chart, and Diagram Interpretation: Multimodal models can read structured visuals such as charts, graphs, and diagrams. They extract insights, summarize reports, and explain patterns found in visual data.
- Audio and Speech Understanding: The model can process spoken language and sound signals. It can transcribe speech, summarize conversations, and interpret tone or context from audio inputs.
- Video Understanding and Temporal Reasoning: These systems analyze sequences of frames in videos. They recognize actions, track events over time, and explain what happens across different moments.
- Cross-modal Reasoning Across Inputs: The model connects information across formats. For example, it can combine text instructions with an image or video to produce a more accurate response.
By combining these capabilities, multimodal language models move beyond simple pattern recognition and begin to understand information across formats in a more connected and meaningful way.
Popular Multimodal LLMs and Vision Language Models
Several AI systems today combine language with visual and audio understanding. At this stage, it’s worthwhile to look at the main model families shaping multimodal AI today.
The table below highlights a few well-known examples.
| Model Category | Key Capability | Typical Uses | Example Models |
| GPT Multimodal Models | Integrate language reasoning with image and sometimes audio inputs | Visual Q&A, document analysis, coding help, & AI assistants | GPT-4V, GPT-4o |
| Gemini Multimodal Models | Designed to handle text, images, audio, and video within a unified architecture | Research tools, complex reasoning tasks, & multimodal assistants | Gemini 1.5 Pro |
| Claude Multimodal Models | Focus on strong reasoning with support for image inputs and long context | Document interpretation, enterprise analysis, & knowledge tasks | Claude 3.5 Sonnet |
| Open-Source Vision-Language Models | Combine vision encoders with language models for visual understanding tasks | Visual reasoning, research experiments, & custom AI systems | LLaVA, BLIP-2 |
These models show how multimodal AI is evolving, from research systems focused on images and text to large models capable of interpreting several types of data in a single interaction.
Limitations and Challenges of Multimodal LLMs
Handling various data types makes multimodal LLMs more complex than traditional language models. Despite their rapid progress, these models still face several technical and practical challenges.
Understanding these limitations is important when designing or deploying real-world multimodal AI systems.
Multimodal Hallucinations and Reasoning Errors
Multimodal models can still generate incorrect interpretations when visual or audio inputs are ambiguous.
For example, the model may misidentify objects or infer relationships that are not present, like describing a dog as a wolf in a blurry image or assuming two people in a photo are interacting when they are not.
How to Overcome It: Use better training datasets, stronger evaluation benchmarks, and human feedback to improve model reliability.
High Training and Computing Costs
Training multimodal systems requires massive datasets and specialized hardware.
Processing images, video, and audio alongside text significantly increases computational cost.
How to Overcome It: Techniques like model optimization, parameter-efficient training, and selective modality processing can help reduce costs.
Data Alignment Challenges Across Modalities
Different data formats must be mapped into a shared representation, which is technically difficult. Poor alignment can weaken reasoning across modalities.
How to Overcome It: Improved multimodal training strategies and better alignment models help maintain consistency between inputs.
Long Context and Video Understanding Limits
Video data involves many frames and long time sequences, which can overwhelm the model context limits.
How to Overcome It: Frame sampling, hierarchical processing, and improved long-context architectures can improve performance.
Safety and Bias Concerns
Multimodal models can inherit bias from training data or misinterpret sensitive visual or audio content.
How to Overcome It: Stronger safety filters, balanced datasets, and continuous monitoring help reduce harmful outputs.
While these challenges are real, they are solvable with the right model architecture, training strategy, and evaluation pipeline.
Experienced AI teams like Relinns Technologies often help organizations design and deploy reliable multimodal LLM systems while balancing cost, performance, and safety.
Exploring the Future of Multimodal LLMs
With rapid advancements in multimodal AI architectures, we are entering an era where models treat video, audio, and live data as equals. AI is now a native observer that can sense, reason, and act in real-time.
Here are some insights that highlight emerging directions depicting the future of multimodal LLMs:
Audio-Visual Language Models
Modern models do more than transcribe speech. They hear tone and emotion while watching facial expressions.
This unified understanding allows AI to catch subtle cues, like a customer’s frustration or a machine’s mechanical whine, that text-only systems would never notice.
Video-Native Multimodal Models
New architectures understand time and physics. They don’t just look at static frames; they understand how objects move and interact.
This can become the backbone for predicting equipment failure or identifying complex security risks before they even happen.
Real-Time Multimodal Reasoning
Latency is steadily decreasing with advances in model optimization and hardware.
This allows AI to act as a “second pair of eyes” for professionals like surgeons or engineers. The model can also process live camera feeds and offers instant feedback.
AI is moving from a slow chat interface to a real-time partner in high-stakes environments.
Multimodal Agents and Autonomous Systems
The biggest shift is agency. Models can now “see” a software interface and navigate it like a human.
They click buttons, fill forms, and manage workflows across different apps. They aren't just giving advice; they are actually doing the work for you.
The future of multimodal LLMs lies in deeper perception and faster reasoning. As models improve, AI will become more aware of the world around it.
Final Thoughts
Multimodal LLMs mark an important shift in how artificial intelligence understands information.
Instead of relying on one type of input, these models bring different signals together to form a clearer picture of what is happening. This makes AI more useful for real-world problems where context matters.
As the technology evolves, these systems will support better decision-making, smarter digital assistants, and new forms of automation across industries. At the same time, challenges like reliability, cost, and safety still need attention.
Multimodal LLMs are not just an upgrade to language models; they represent a new direction for intelligent systems.
Frequently Asked Questions (FAQs)
What is a Multimodal LLM?
A multimodal LLM is an AI model that processes multiple types of inputs, such as text and visuals together, allowing it to interpret context and generate more informed responses.
How is a Multimodal LLM Different from a Traditional LLM?
Traditional LLMs mainly analyze written language, while multimodal LLMs combine additional signals, enabling them to interpret richer information and produce more context-aware responses.
How are Multimodal LLMs Different from Vision-Language Models?
Vision-language models focus on connecting visuals with text. Multimodal LLMs extend this idea by combining multiple encoders with a language model for deeper reasoning.
What are Some Examples of Multimodal LLMs?
Popular multimodal LLMs include GPT-4V, Gemini 1.5 Pro, and Claude 3.5 Sonnet. These models can interpret visual inputs and generate detailed responses.
What are Multimodal LLMs Used for?
They are used in AI assistants, document analysis, visual reasoning, healthcare diagnostics, and research tools where understanding multiple information sources improves accuracy and decision-making.
What are the Main Challenges of Multimodal LLMs?
Key challenges include hallucinations, high training costs, aligning different data formats, and ensuring safety. Researchers are developing improved architectures and training methods to address these issues.
What is the Future of Multimodal LLMs?
The future of multimodal LLMs lies in real-time reasoning, improved video understanding, and AI agents that can interpret complex environments and assist humans in high-stakes decisions.
Can Multimodal LLMs Understand Videos?
Yes, multimodal LLMs can analyze videos by processing sequences of frames and associated audio, allowing them to recognize actions, track events, and explain what happens over time.



