LoRA vs QLoRA vs Full Fine-Tuning: A Decision Framework
The Modern PEFT Frontier Beyond LoRA
Enterprise Use Cases for Parameter-Efficient Fine-Tuning
Operational Considerations & Common Risks in PEFT
How to Evaluate if PEFT is Right for Your Organization
Final Thoughts
Frequently Asked Questions (FAQs)
Share
Link Copied
Most AI models are too big to train from scratch. Even powerful computers struggle, and training them can cost millions.
Only a few companies can afford that kind of gamble. However, there’s a smarter way to handle customizing AI for specific business needs, i.e., instead of redoing the entire model, you adjust only the parts that matter.
That’s where parameter-efficient fine-tuning comes in. The approach makes AI faster, cheaper, and safer to use. Methods like LoRA fine-tuning and QLoRA fine-tuning let companies shape large AI models for specific tasks without a huge investment. You get expert-level AI performance without the massive cost or complexity.
This guide explains exactly how business leaders, data teams, and AI managers can adopt PEFT methods to save time, decrease computing costs, and improve ROI.
Why Parameter-Efficient Fine-Tuning Matters for Enterprise AI
Large AI models are powerful, but adapting them is expensive. Training from scratch means heavy spending and blocking of valuable infrastructure.
Unsurprisingly, many organizations struggle to grow AI effectively while keeping expenses and resources under control.
Cost Challenges with Full Model Fine-Tuning
The bigger the AI model, the more computing power it needs. On one hand, the hardware costs soar. On the other hand, energy bills add up.
Full fine-tuning also slows other projects because resources are tied up.
How PEFT Reduces Infrastructure and Compute Burden
Parameter-efficient fine-tuning changes only a small part of the model. This approach drastically cuts GPU and memory needs.
When fewer resources are locked, teams can run multiple experiments without extra costs.
Faster Experimentation and Time-to-Market
Because PEFT is lighter, teams can test ideas faster. Models can be adapted and deployed quickly.
Businesses often use parameter-efficient fine-tuning LoRA to adapt large AI models and get actionable AI solutions sooner, without the months-long delays of full model retraining.
To gain a considerable advantage, many teams also partner with AI experts like Relinns Technologies that provide proven workflows and support, helping teams implement parameter-efficient fine-tuning while keeping costs and risks under control.
What Parameter-Efficient Fine-Tuning Actually Means
Parameter-efficient fine-tuning is a smarter way to customize AI models without retraining everything.
Instead of rewriting the full model, it focuses on adjusting only the parts that matter. This keeps the base model stable while letting teams adapt AI for specific tasks.
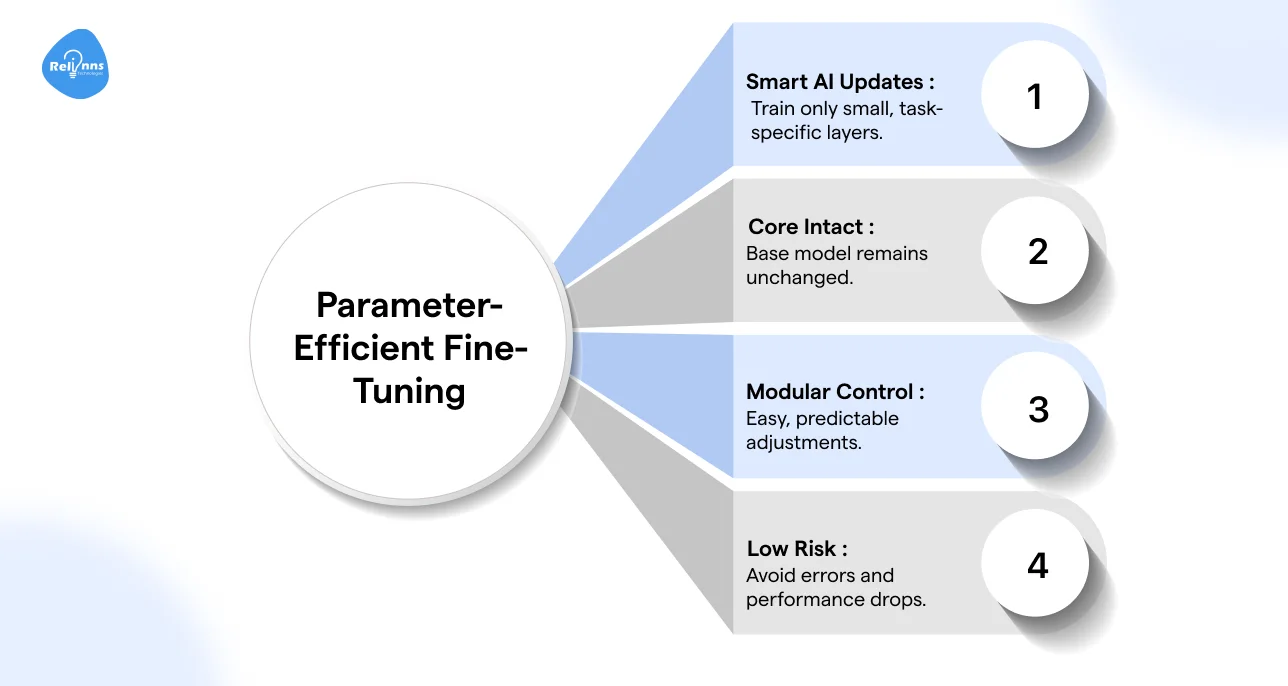
With parameter-efficient fine-tuning, you don’t touch the entire AI model. Instead, you:
Freeze Foundation Models, Train Small Parameter Layers: Base weights (the main brain) remain untouched. Only lightweight layers are trained for your specific task.
Adapt in a Controlled, Modular Way: This makes AI changes predictable and easier to manage.
Lower Risk of Errors: Reduces catastrophic forgetting and avoids performance degradation
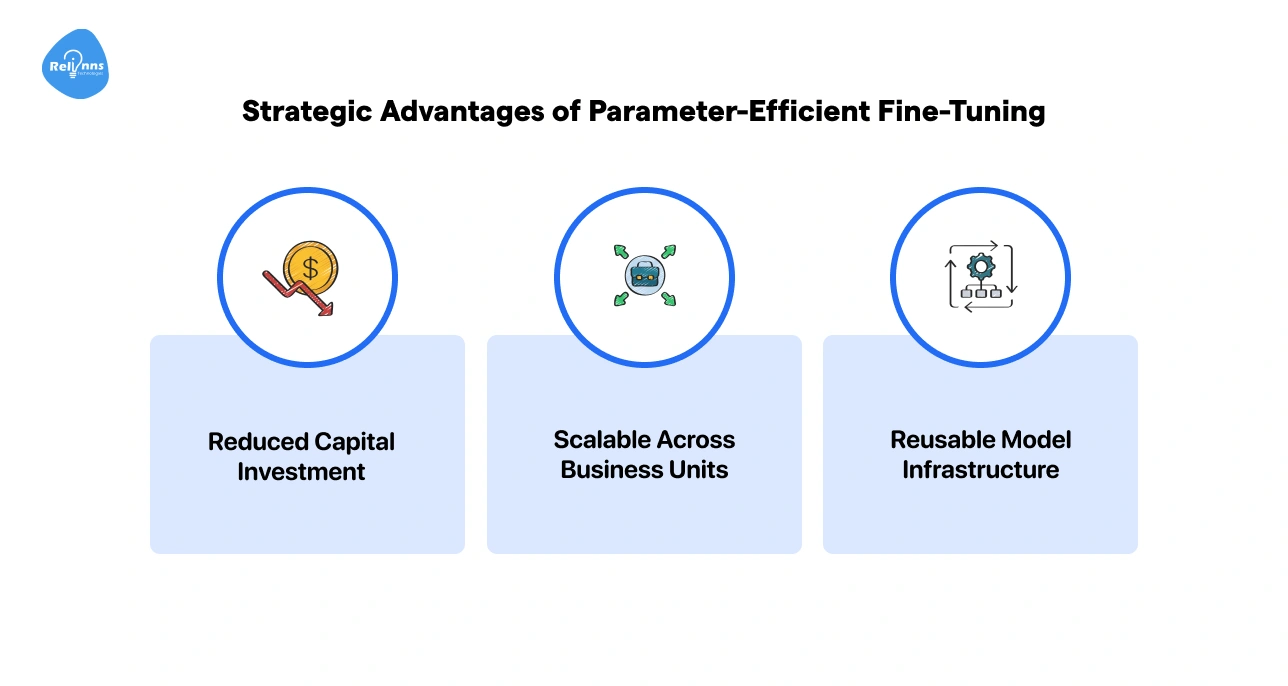
Strategic Advantages of Parameter-Efficient Fine-Tuning
Adopting this method gives businesses clear benefits in cost, scalability, and efficiency.
Reduced Capital Investment: Only small parts of the model are updated, saving computing costs.
Scalable Across Business Units: The same foundation model can serve multiple teams or products.
Reusable Model Infrastructure: Adapters and small layers can be reused for new tasks, speeding up future projects.
LoRA Fine-Tuning: A Key Method
LoRA (Low-Rank Adaptation) fine-tuning is one of the most popular and leading PEFT methods.
It allows targeted adaptation without touching the full model. Businesses get efficient, task-ready AI with lower cost, lower risk, and faster deployment.
Customizing large AI models doesn’t have to mean retraining everything.
LoRA fine-tuning and QLoRA (Quantized Low-Rank Adaptation) fine-tuning are the two key PEFT methods that let businesses fine-tune massive models by tweaking only a tiny fraction of the model’s parameters. This keeps your costs down and your performance high.
Here’s a side-by-side overviewof LoRA and QLoRA fine-tuning:
Feature
LoRA Fine-Tuning
QLoRA Fine-Tuning
How it Works
Adds low-rank adapters to the model
Shrinks the model first, then adds adapters
Parameters Updated
Minimal, targeted within transformer layers
Minimal, memory-efficient for large models
Best For
High-stakes tasks, incremental enhancements, and deep specialization
Limited GPU setups, cost-sensitive AI programs, pilot scaling
Requirements
Needs a solid, mid-to-high tier GPU
Runs on modest, smaller hardware
Trade-offs
High accuracy with moderate resource needs
Slight precision trade-offs for lower memory usage
Key Takeaways:
LoRA fine-tuning is best when you have the hardware and accuracy, or task specialization, as top priorities.
QLoRA fine-tuning is ideal for limited hardware or when you’re running massive models on a single GPU.
Both methods offer efficient, scalable, and low-risk ways to adapt AI for business needs.
Now that we’ve explored how LoRA and QLoRA work individually, it’s time to see how they stack up against full model fine-tuning.
LoRA vs QLoRA vs Full Fine-Tuning: A Decision Framework
Fine-tuning AI isn't just a dev task; it’s a business strategy.
Leaders must balance speed-to-market against infrastructure costs. While full Fine-Tuning offers total control, LoRA and QLoRA provide the agility needed for modern enterprise scaling.
The table below helps you quickly compare and interpret the implications of each fine-tuning method.
Feature
LoRA
QLoRA
Full Fine-Tuning
Cost
Budget-friendly
Low-to-medium
Very high
Hardware / Infrastructure
Mid-tier GPU
Modest GPU, memory-efficient
High-end GPUs, multiple nodes
Time to Market
Fast, easy adaptation (rapid delivery)
Fast with small trade-offs
Slow, full retraining required
Risk & Stability
Low risk, base model intact
Low risk, minimal precision trade-offs
Higher risk of breaking the model or “forgetting”
Scalability
High (reusable adapters, easy across teams)
Max (reusable, works with limited hardware)
Low (each team may need separate model)
Performance
High for targeted tasks
Slight precision trade-offs
Maximum accuracy & flexibility
Which Path is Right for You?
LoRA: Your “go-to” for high accuracy without overloading infrastructure.
QLoRA: The best way to run massive models on limited, everyday hardware.
Full Fine-Tuning: Reserved for when you need deep, fundamental model changes and have the budget to match.
The Bottom Line: For most businesses, LoRA and QLoRA offer the smartest path to ROI by reducing risk and deployment time.
The Modern PEFT Frontier Beyond LoRA
Parameter-efficient fine-tuning has grown beyond just LoRA and QLoRA.
Modern PEFT techniques give businesses more flexibility, modularity, and speed when adapting large AI models.
These methods allow teams to customize models without full retraining, keeping costs low and deployment predictable.
Adapters and Modular Model Customization
Adapters let you add small, task-specific components to a base model.
They preserve the foundation, allow the model to handle multiple tasks at once, and make updates simpler and faster for teams.
Prompt and Prefix Tuning for Lightweight Adaptation
Instead of changing model weights, these methods adjust inputs or prefixes.
This approach supports quick experimentation, easy adaptation, and lower computing costs.
Emerging Techniques: DoRA and Hybrid Approaches
New PEFT methods, like DoRA (Weight-decomposed Low-Rank Adaptation), combine multiple fine-tuning techniques by breaking down model weights into smaller components.
This approach boosts stability, improves performance across languages, and allows incremental updates.
These innovations give businesses more flexible and efficient ways to fine-tune AI models without retraining everything.
Enterprise Use Cases for Parameter-Efficient Fine-Tuning
Parameter-efficient fine-tuning lets you customize AI fast and affordably.
With LoRA and QLoRA, high-performance AI is finally accessible for every industry.
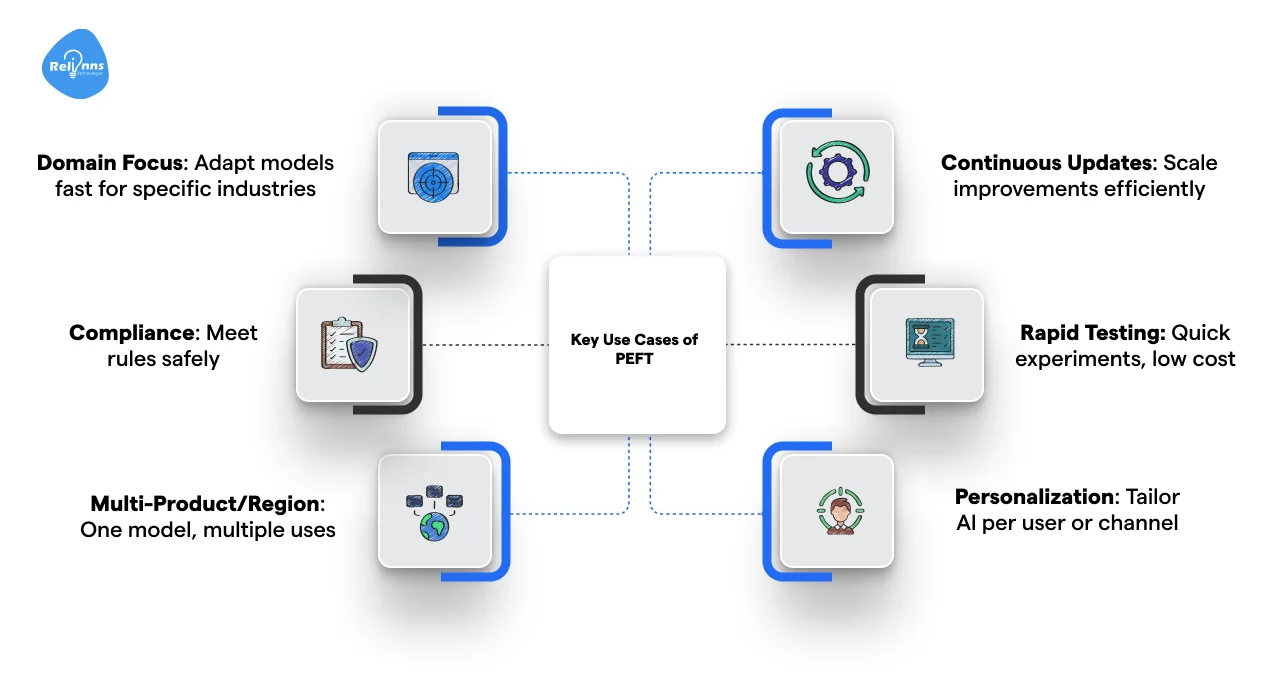
Key Use Cases of PEFT
When teams focus only on the parts that matter, it leads to faster deployment and more reliable AI performance.
Domain Specialization Without Full Retraining: Customize AI models for finance, health, or law while keeping your base model intact.
Compliance and Regulatory Adaptation: Meet strict industry rules through surgical updates that don't compromise your data security.
Multi-Product & Multi-Region Deployment: Use a single foundation model with adapters for different products or markets.
Continuous Model Improvement at Scale: Roll out iterative upgrades and boost performance without the heavy price tag of full retraining.
Rapid Experimentation & Innovation: Test new features and workflows quickly and safely without heavy compute investment.
Personalization at Scale: Pivot your AI for specific customers or channels without starting from square one every time.
Before adoption, businesses must also consider operational requirements and potential risks to ensure AI remains dependable, secure, and cost-effective.
Operational Considerations & Common Risks in PEFT
Using parameter-efficient fine-tuning goes beyond picking a method.
Companies need to plan for control, data handling, vendor choices, and measurable results to make sure LoRA or QLoRA projects run smoothly and deliver real business value.
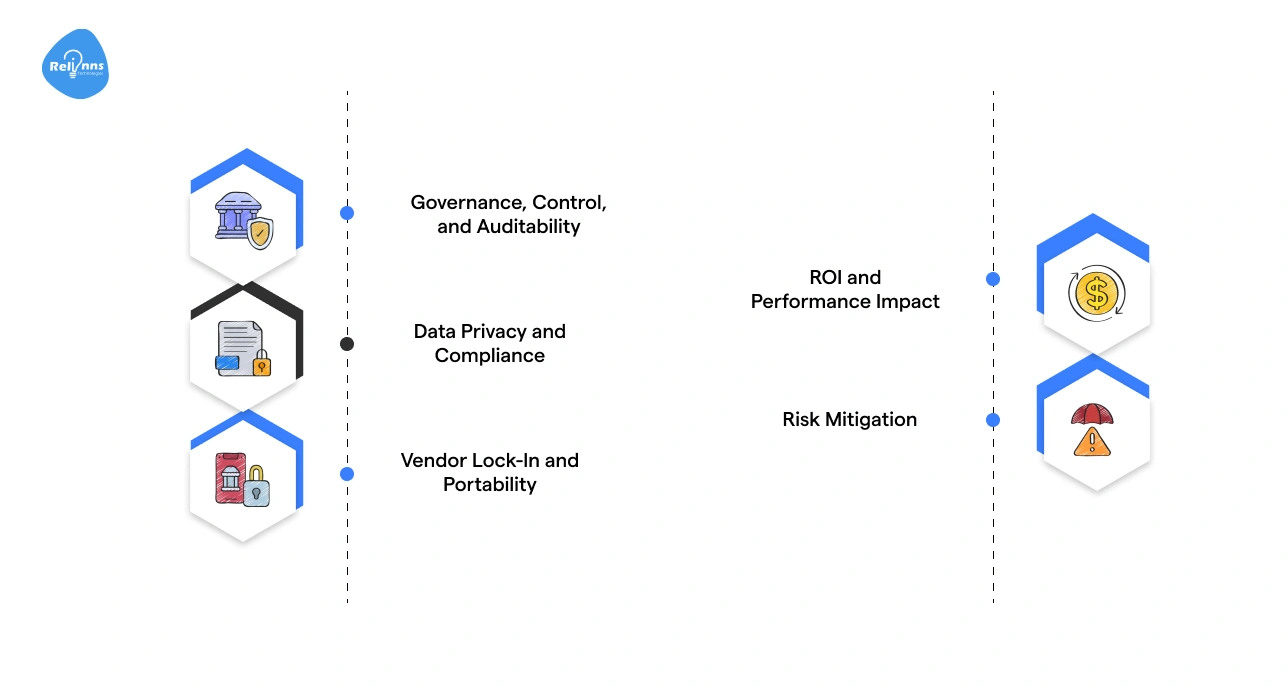
Some of the core PEFT considerations and risks include:
Governance, Control, and Auditability
Challenge: Updates and adapter versions can get messy without clear oversight.
The Fix: Define ownership and approval workflows so every change is documented and validated.
Data Privacy and Compliance
Challenge: Training data may contain sensitive information or fall under strict regulations.
The Fix: Use anonymized or synthetic data and modular adapters to minimize exposure.
Vendor Lock-In and Portability
Challenge: Relying on a single vendor can limit flexibility and future options.
The Fix: Standardize adapters and maintain portable model configurations to stay adaptable.
ROI and Performance Impact
Challenge: It’s easy to spend resources without knowing the real business value.
The Fix: Track measurable KPIs like speed-to-market, cost per improvement, or accuracy gains.
Risk Mitigation
Challenge: Over-customization or infrastructure misplanning can lead to failures.
The Fix: Start small, benchmark results, and scale gradually to reduce risk.
Overcoming these challenges is imperative to ensure your AI projects deliver consistent results, stay on budget, and scale effectively across the business.
With these operational factors and risks in mind, the next step is deciding if PEFT methods like LoRA or QLoRA are the right fit for your organization.
How to Evaluate if PEFT is Right for Your Organization
Not every organization is ready for parameter-efficient fine-tuning.
Executives must consider budget, infrastructure, internal AI maturity, and long-term plans to determine whether LoRA or QLoRA is a good fit.
Making the right choice early saves cost, time, and risk.
Quick Evaluation Table
Use this simple framework to see at a glance whether PEFT methods like LoRA or QLoRA fit your organization’s needs.
Factor
Indicator
PEFT Readiness
Business Impact
Budget & Infrastructure
Mid-tier or limited GPUs available
LoRA or QLoRA feasible
You can fine-tune models without overspending on hardware.
AI Maturity & Capability
Experienced ML/AI team & ops
Can adopt PEFT effectively
Teams can implement tuning safely and maintain high performance.
Long-Term AI Roadmap
Need scalable, modular AI across products
PEFT aligns with growth plans
Supports multiple business units and future expansion efficiently
Decision: If your organization meets most indicators, LoRA or QLoRA fine-tuning can deliver fast, cost-efficient AI adaptation.
For organizations exploring PEFT, having the right tools and expertise makes a difference.
Trusted technology partners like Relinns Technologies provide guidance, infrastructure support, and proven workflows to help teams implement LoRA or QLoRA fine-tuning efficiently.
Adapting large AI models doesn’t have to be slow or expensive.
With parameter-efficient fine-tuning, methods like LoRA and QLoRA let teams change only what matters, saving time, money, and computing power. These methods support faster experimentation, targeted domain customization, and scalable deployment across teams and products.
Before getting started, it’s important to consider budget, hardware, and your team’s AI experience. With the right planning, PEFT can deliver real business value without the headaches of full retraining.
PEFT isn’t just a technical choice; it’s a strategic approach to making enterprise AI smarter, faster, and more accessible.
Frequently Asked Questions (FAQs)
What is parameter-efficient fine-tuning, and how does it differ from full fine-tuning?
PEFT updates only a small part of a model, saving time and cost. Full fine-tuning changes all parameters, making it slower and more expensive.
How do LoRA fine-tuning and QLoRA fine-tuning actually work?
LoRA adds small adapters to a frozen model for targeted learning. QLoRA compresses the model first, allowing large models to be tuned on smaller hardware.
Will parameter-efficient fine-tuning hurt model accuracy?
PEFT generally maintains accuracy close to full fine-tuning. QLoRA’s compression may cause tiny precision differences, usually negligible for real business tasks.
Can QLoRA really fine-tune very large models on a single GPU?
Yes. QLoRA uses quantization and trains only adapters, enabling huge models to run on a single modest GPU instead of multiple high-end cards.
How do I choose between LoRA, QLoRA, and full fine-tuning?
Pick based on hardware and goals: LoRA for accuracy, QLoRA for limited resources, full fine-tuning for big, task-specific changes.
What are common mistakes when using PEFT methods?
Assuming PEFT fixes bad data is a mistake. Noisy data affects results, so always use clean, high-quality training examples.
Recommended for you
AI Voice Agents
Speech-to-Speech vs STT-LLM-TTS: Clear Choice for AI Voice Agents
AI Voice Agents
Barge-In in Voice Agents: Why Turning It On Isn't Enough
AI Voice Agents
Semantic VAD for Voice Agents: How Turn Detection Actually Works in 2026
AI Voice Agents
Best TTS for Voice Agents in 2026: A Buyer's Framework, Not a Ranking