

What Is Multimodal AI? Understanding Images, Audio & Video
Date
Jul 02, 26
Reading Time
12 Minutes
Category
Generative AI
Share
AI is no longer just about text.
It’s learning to see, hear, and understand the world, just like humans. Machines are now interpreting images, audio, video, and text all at once.
This shift is marked by multimodal AI, a type of artificial intelligence that processes multiple types of information together. Modern systems like GPT-4o, Gemini, and Claude are leading this shift, showing how machines can reason across text, images, and audio.
In this guide, you’ll learn “what is multimodal AI”, how it works, the models behind it, and real-world examples of its impact. By the end, you’ll understand why it’s shaping the next era of AI.
What is Multimodal AI? A Human-Like Understanding Across Data
Multimodal AI is a type of artificial intelligence that can understand and process multiple types of information at the same time, like text, images, audio, and video.
Unlike traditional AI, it doesn’t rely on just one input.
Example: A model that can read a product review, analyze an image of the product, and listen to a customer comment to give a complete recommendation.
Technically Speaking
From a technical perspective, multimodal AI combines features from different modalities into a shared representation, enabling the model to reason across them.
It uses encoders for each data type, aligns them in a common space, and applies fusion mechanisms to generate outputs.
Core Characteristics of Multimodal AI
Multimodal AI stands out because it can handle diverse data types and reason across them. Its main features include:
- Handles multiple input types simultaneously
- Performs cross-modal reasoning
- Can generate outputs in one or more modalities (it can produce text descriptions, create images, or generate speech)
- Learns from aligned datasets across modalities
Multimodal AI vs Other AI Types
For a better understanding of how multimodal AI differs from other AI systems, the table below breaks down the key differences:
| AI Type | Input/Focus | Key Difference |
| Unimodal AI | Single type (text or image) | Limited to one type of data |
| Generative AI | Content creation | Focused on generating output, usually single modality |
| Multimodal AI | Multiple types | Understands, reasons, and generates across modalities |
Thus, multimodal AI combines the strengths of both unimodal and generative AI to deliver more natural, human-like understanding across text, images, audio, and video.
Companies looking to run their own multimodal AI systems often team up with experienced AI and data experts like Relinns Technologies to design solutions that seamlessly combine text, images, audio, and video into smarter, context-aware insights.
Why Multimodal AI Matters: Decoding the Key Benefits
Multimodal AI is changing how machines understand and interact with the world. Its key advantages make technology more human-like, accurate, and personalized.
- Human-Like Context Understanding: Can interpret multiple inputs together, like reading a text while analyzing an image or listening to audio
- Cross-Modal Reasoning: Links insights across modalities to make smarter decisions and predictions.
- Improved Accuracy and Robustness: Combining data types reduces errors and improves model reliability.
- Enhanced Personalization: Delivers tailored recommendations, content, or responses based on richer information.
- Natural Interaction: Supports seamless experiences across text, images, audio, and video, making AI more intuitive and engaging.
One of its notable examples is GPT-4o, which can process text, images, and audio together to provide context-aware responses.
These benefits are why multimodal AI is at the forefront of the next AI evolution, powering smarter applications in healthcare, retail, education, and beyond.
How Multimodal AI Works: From Raw Data to Human Insight
Multimodal AI processes different types of data to understand and generate meaningful outputs. The process can be broken down into four critical stages:
| Step | Phase | What Happens | Real-World Examples |
| 1 | Input Encoding | Translates raw data (pixels/sound) into “math” the AI understands | Text embeddings, image encoders, video frames |
| 2 | Cross-Modal Alignment | Matches concepts across types (linking the word “dog” to a photo of a dog) | Shared mathematical spaces, contrastive learning |
| 3 | Fusion Mechanisms | Blends the data streams to find deeper patterns and meaning | Early/late fusion, cross-attention layers |
| 4 | Output Generation | Produces a final response based on its holistic understanding | Image captioning, video summaries, speech |
Each of these steps is further broken down to show how data flows from input to actionable insights.
Step 1: Input Encoding Across Modalities
Each type of data is first converted into a numerical representation that the AI can understand.
Text uses embeddings, images pass through encoders, audio features are extracted, and video frames are modeled.
Example: Converting a news article, an accompanying chart image, and a recorded interview into machine-readable vectors
Step 2: Cross-Modal Alignment
The AI aligns all modalities in a shared space.
This allows it to compare and link information from different sources. Contrastive learning helps the model understand which inputs match or relate.
Example: Aligning a product specification document with demo videos and customer support audio to extract consistent insights
Step 3: Fusion Strategies & Mechanisms
The encoded data is combined using fusion strategies. Early fusion mixes inputs upfront. Intermediate and late fusion merge them later.
Transformers and cross-attention mechanisms allow interactions between modalities for deeper reasoning.
Example: Combining sensor readings, video footage, and operator notes to detect anomalies in a factory process
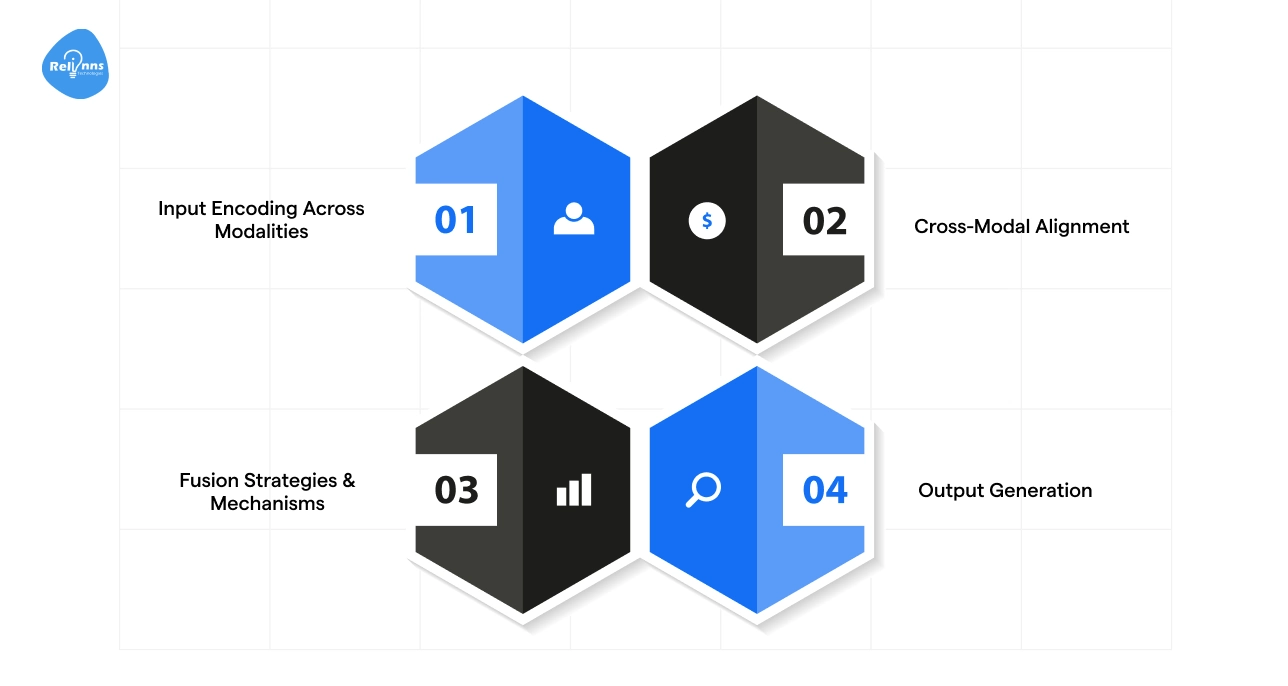
Step 4: Output Generation
Finally, the AI produces outputs. This could be text summaries, image generation, speech, or insights that combine multiple data types.
Example: Producing a dashboard report with text highlights, annotated images, and audio alerts
Together, these steps enable multimodal AI to understand, reason, and generate insights across multiple types of data, delivering more precise results.
How Multimodal AI Processes Each Data Type
Multimodal AI doesn’t treat all data the same. Each type (text, images, audio, or video) has its own way of being understood.
Here’s a closer look at how multimodal AI models handle them:
Text Processing
- Breaks text into smaller units called “tokens”
- Uses transformer-based models to understand the meaning and context of the text
- Captures intent, relationships, and nuances in language
- Converts text into embeddings that the AI can work with
Image Processing
- Uses CNNs or vision transformers to extract key features
- Detects objects, patterns, and spatial relationships
- Helps the AI “see” and understand images in context
- Produces embeddings ready to combine with other modalities
Audio Processing
- Turns audio into spectrograms for analysis.
- Recognizes speech and identifies tone or emotion.
- Captures subtle details in sound that help reasoning.
- Creates audio embeddings for use in multimodal artificial intelligence systems.
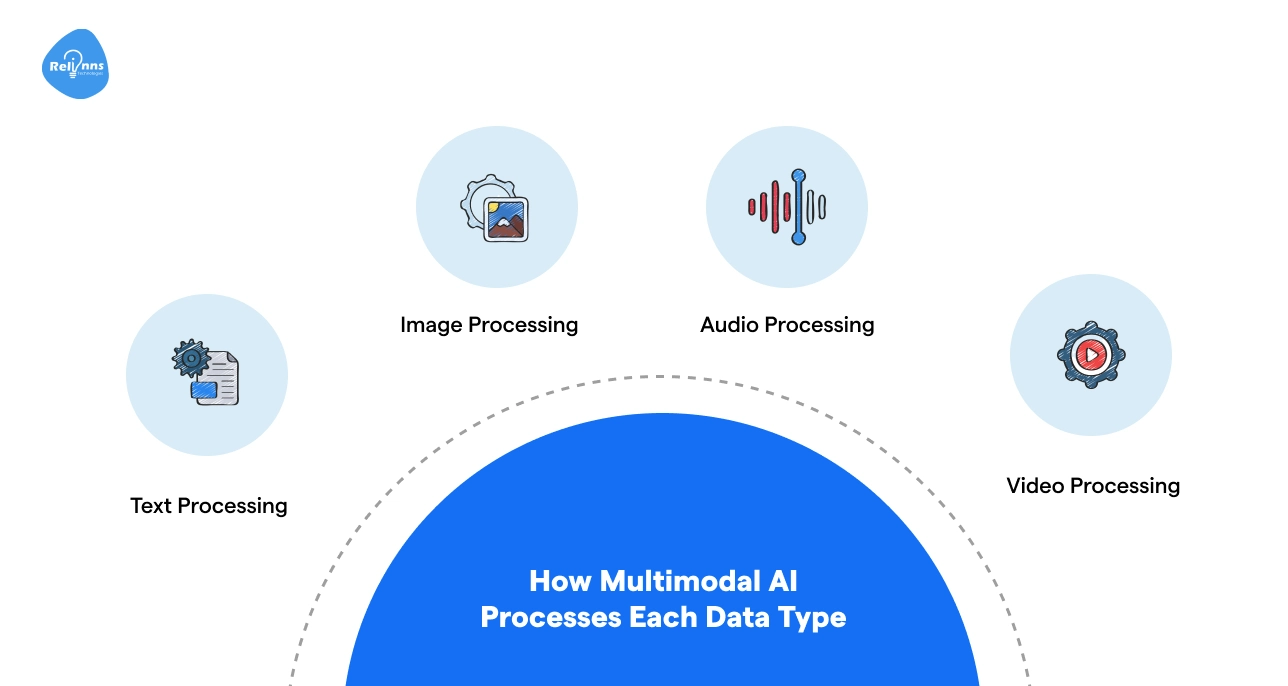
Video Processing
- Looks at sequences of frames to capture motion and events
- Uses spatio-temporal transformers to connect visual and temporal features
- Understands actions, patterns, and changes over time
- Produces video embeddings that integrate with text, image, and audio
By processing each type of data this way, multimodal AI systems can combine insights across modalities, making sense of complex inputs and generating richer, smarter outputs.
Multimodal AI Model Architectures: The Building Blocks of Intelligent AI
The architecture of a multimodal AI model defines how it processes and combines different types of data.
Choosing the right design impacts accuracy, speed, and flexibility. There are four common approaches used in modern multimodal AI models.
Modular Architectures
Each modality has its own separate encoder. A fusion layer combines the outputs into a shared representation.
This architecture is easy to customize or add new modalities, and it works well when modalities have very different data types.
Think of it as a team where each expert focuses on their specialty, then combines insights to make smarter decisions.
Cross-Attention Architectures
Cross-attention architecture uses a main backbone (like a language model) and adds adapters for other modalities.
These layers allow the model to focus on relevant parts of each input. They enable stronger interaction between modalities and are popular for vision-language tasks.
For instance, linking specific words in a caption to regions in an image.
Unified Transformer Models
A single transformer handles all modalities together. These models process text, images, audio, and video in one unified architecture.
It simplifies model deployment and allows general-purpose reasoning.
Examples include GPT-4o, Gemini, and Claude.
Generative Multimodal Models
Generative models are designed to create content across modalities.
They support text-to-image, text-to-video, or mixed content generation. These models are useful for creative applications, simulations, and content augmentation, including tools like face swap AI that use generative techniques to seamlessly replace faces in images and videos.
DALL·E and Runway Gen-2 are some common multimodal AI examples in this field.
These architectures show how multimodal artificial intelligence combines data intelligently to generate richer insights and outputs.
Real-World Multimodal AI Examples & Use Cases
Multimodal AI is no longer theoretical; it’s powering real systems across industries.
The world today sees many advanced multimodal AI models in action that understand, reason, and generate insights across formats.
Here’s a breakdown of some of the most notable models and how they are applied across industries:
| Model | Supported Modalities | Strengths | Key Applications |
| GPT-4o | Text, images, audio | Cross-modal reasoning, general-purpose | Chatbots, content understanding, analysis, multimodal Q&A |
| Gemini | Text, images, video | Strong cross-modal reasoning, massive context (1M+ tokens), video analysis | Productivity tools, enterprise workflows, long-form research, video indexing |
| Claude 3 | Text, images, documents | Safe multimodal processing, document analysis, complex PDF reasoning | Enterprise QA, report summarization, legal/finance, technical auditing |
| CLIP / LLaVA | Text, images | Open multimodal embeddings, zero-shot visual matching | Visual search, medical imaging, academic research, image-text alignment |
| Other Open-Source Models | Varies | Flexible, customizable | Experimentation, research, prototypes |
On the whole, these models are powerful examples of how multimodal AI combines text, images, audio, and video to deliver smarter, context-aware insights.
Now that we’ve understood the key multimodal AI models and their capabilities, it’s time to take a closer look at the application of multimodal artificial intelligence across industries.
Industry Applications of Multimodal Artificial Intelligence
Multimodal AI is transforming how industries operate by combining multiple data types to deliver smarter, faster, and more context-aware solutions.
| Sector | Multimodal AI Use Cases |
| Healthcare | Medical imaging + patient notes analysis |
| Retail & Ecommerce | Product recommendations, visual search |
| Autonomous Vehicles | Sensor fusion for safe navigation |
| Robotics | Vision and audio integration for tasks |
| Education | Interactive learning with text, audio, video |
| Accessibility | Real-time captions, image-to-text tools |
These applications demonstrate how multimodal artificial intelligence turns complex data into actionable insights, improves decision-making, and creates more intuitive user experiences across industries.
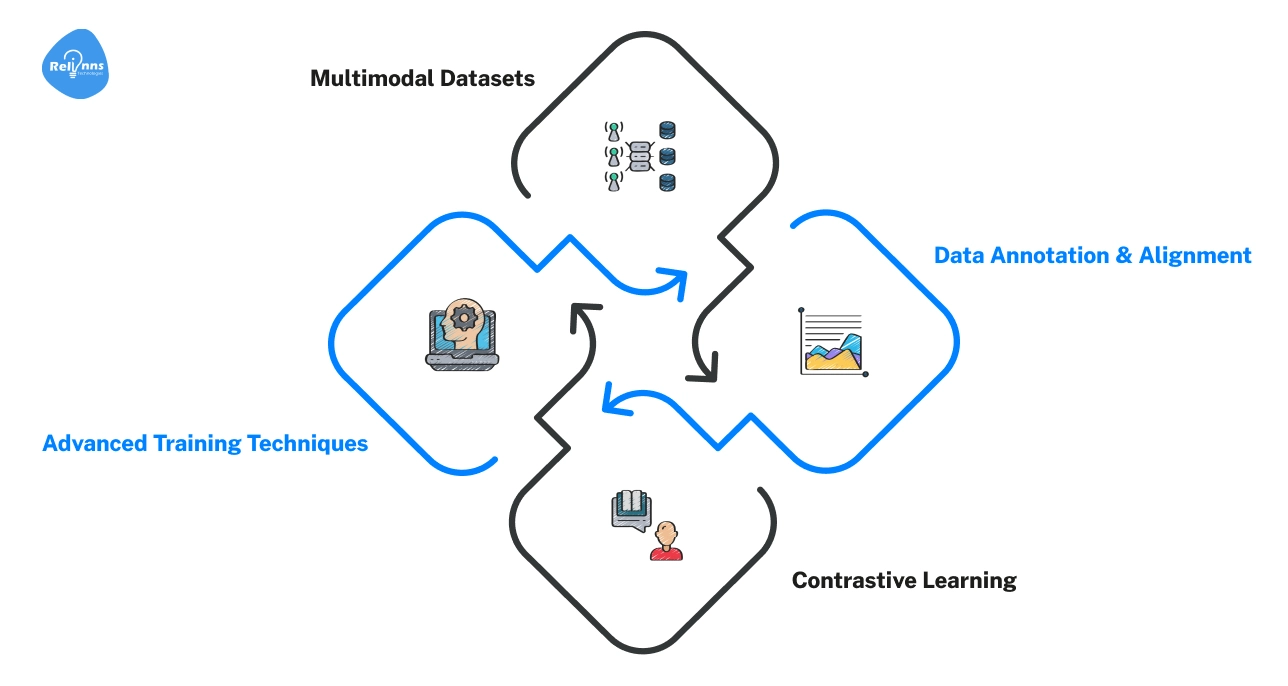
Training Multimodal AI Models: How Data Becomes Intelligent
Training multimodal AI models is what turns raw data into intelligent systems that can understand text, images, audio, and video together.
It’s a mix of careful data preparation and advanced learning techniques.
- Multimodal Datasets → Start with diverse, high-quality data covering all relevant modalities.
- Data Annotation & Alignment → Label and align data across modalities so the AI can learn correlations (text matches image, audio matches video, etc.).
- Contrastive Learning → Next, the model learns to bring related inputs closer in embedding space and push unrelated ones apart.
- Advanced Training Techniques → Finally, fine-tuning, reinforcement learning, or synthetic data generation improves performance or adapts the model to specific tasks.
Across these steps, multimodal AI models progressively learn to connect and reason across different types of data, enabling smarter insights and more context-aware outputs.
Evaluation & Benchmarks for Multimodal AI
Evaluating multimodal AI ensures models understand and reason correctly across text, images, audio, and video.
Metrics measure accuracy, retrieval performance, content generation, and reliability.
| Evaluation Area | What It Measures | Common Metrics / Benchmarks | Typical Performance Range* |
| Visual Question Answering (VQA) | Ability to answer questions about images | VQA v2, GQA, ScienceQA | 60%-85% accuracy depending on model and dataset |
| Cross-Modal Retrieval | Matching content across modalities (e.g., text-to-image) | Recall@K, Precision@K, MRR | Recall@1 often 30%-60% for strong models |
| Generative Evaluation | Quality and coherence of generated text, images, or video | BLEU, ROUGE, FID, Inception Score | BLEU/ROUGE commonly 20-50; FID varies widely (lower is better) |
| Hallucination Detection | Rate of incorrect or ungrounded outputs | Human review, grounding tests | Rates vary significantly; reduction is an active research focus |
| Reasoning & Grounding Tests | Multi-step cross-modal reasoning | Multimodal reasoning benchmarks | Performance varies by task complexity and evaluation protocol |
Using these benchmarks helps ensure multimodal AI models produce trustworthy and meaningful outputs across formats, while giving teams clear targets for performance.
Challenges & Limitations of Multimodal AI
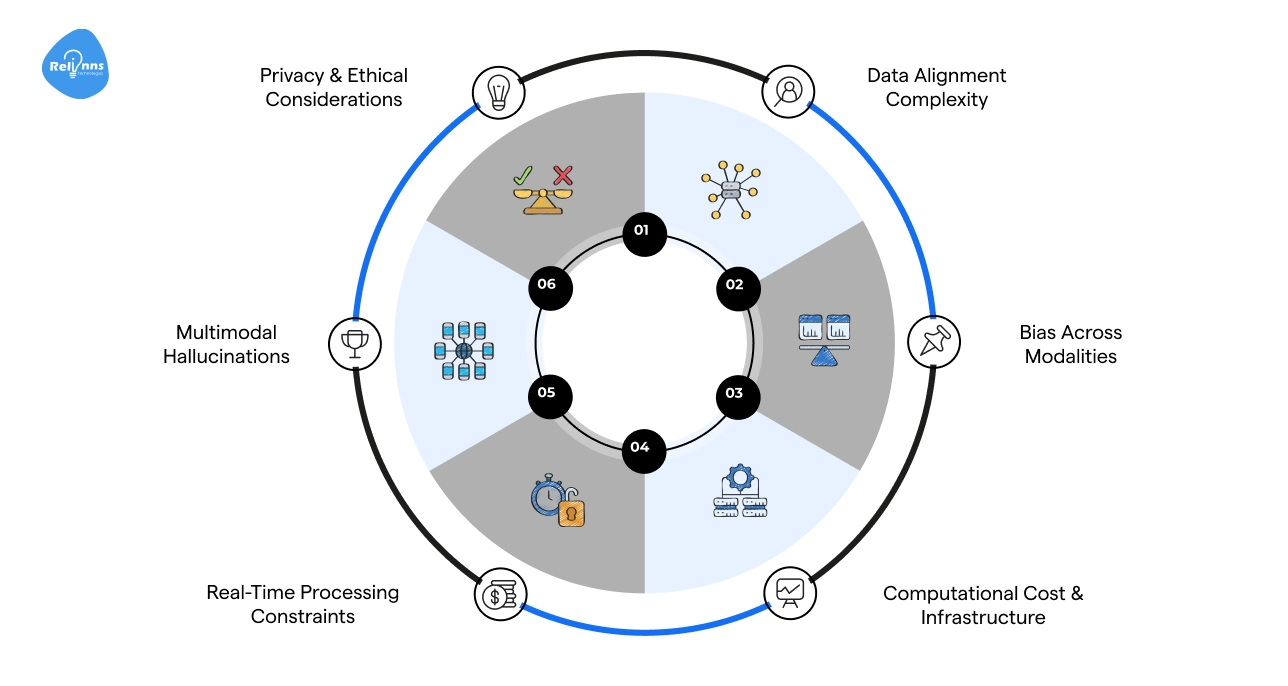
Multimodal AI is powerful, but it comes with real challenges.
From data complexity to bias and infrastructure demands, understanding these limitations helps organizations plan effectively and deploy AI responsibly.
Data Alignment Complexity
Linking text, images, audio, and video correctly is difficult. Misalignment can confuse the model and reduce accuracy.
The Fix: Invest in careful annotation, consistent formatting, and automated alignment tools.
Bias Across Modalities
Models can inherit bias from text, images, or audio, producing unfair or skewed outputs.
The Fix: Audit datasets for representation, balance modalities, and retrain to reduce bias.
Computational Cost & Infrastructure
Processing multiple data types requires high computing and memory.
The Fix: Use optimized architectures, cloud-based GPU/TPU clusters, and model pruning techniques.
Real-Time Processing Constraints
Handling large, diverse inputs can slow responses in live systems.
The Fix: Implement caching, batching, and lightweight inference pipelines.
Multimodal Hallucinations
AI may generate outputs that are inaccurate or irrelevant across modalities.
The Fix: Combine human evaluation, grounding with verified data, and post-processing checks.
Privacy & Ethical Considerations
Sensitive data across modalities may be exposed or misused.
The Fix: Apply strict data governance, anonymization, and compliance standards.
Addressing these challenges ensures multimodal AI remains accurate, fair, and efficient while minimizing risks across applications.
Many businesses aiming to optimize multimodal AI systems partner with Relinns Technologies, leveraging their expertise to create solutions that integrate text, images, audio, and video while meeting industry-standard benchmarks like VQA and cross-modal retrieval.
Final Thoughts
Multimodal AI is changing how machines understand and interact with the world.
By processing text, images, audio, and video together, it enables smarter reasoning, richer insights, and more natural interactions. Modern models like GPT-4o, Gemini, and Claude show what’s possible when AI can connect multiple data types.
While challenges like bias, alignment, and computational demands remain, careful training, evaluation, and design help overcome them.
Multimodal artificial intelligence is not just a technology trend; it represents the next evolution of AI, powering applications across industries and shaping the future of human-like, context-aware systems.
Frequently Asked Questions (FAQs)
What is multimodal AI?
Multimodal AI is artificial intelligence that processes and reasons across multiple data types, including text, images, audio, and video simultaneously.
How does multimodal AI work?
It encodes each modality, aligns them in a shared space, fuses information, and generates outputs across text, images, audio, or video.
What are multimodal AI models?
These are AI systems designed to handle multiple data types, like GPT-4o, Gemini, Claude, CLIP, or LLaVA, enabling cross-modal understanding and reasoning.
What are common applications of multimodal AI?
Healthcare imaging, retail recommendations, autonomous vehicles, robotics, education tools, accessibility aids, and content generation across text, images, and audio.
How is multimodal AI evaluated?
Metrics include VQA for images, cross-modal retrieval, generative evaluation (BLEU/ROUGE/FID), hallucination detection, and reasoning benchmarks for cross-modal accuracy.
What challenges does multimodal AI face?
Key issues include data alignment, bias, high compute costs, real-time constraints, hallucinations, and privacy or ethical considerations.
Why is multimodal AI important?
It enables human-like understanding, improves accuracy, personalization, and reasoning, and powers next-generation AI applications across industries.



