

Supervised Fine-Tuning vs Reinforcement Learning in AI
Date
Mar 11, 26
Reading Time
11 Minutes
Category
Generative AI
Share
Reinforcement learning (RL) won’t automatically outperform supervised fine-tuning (SFT).
Despite the hype, most enterprises still rely on classical fine-tuning to power real products. The belief that one method will replace the other oversimplifies a complex decision.
Model training is not about trends. It is about risk, cost, control, and results. When adapting large language models, leaders face a critical choice: Supervised Fine-Tuning vs Reinforcement Learning.
Each approach changes how models learn, scale, and behave in production. The right decision depends on your data, goals, and tolerance for experimentation.
This guide breaks down the differences between SFT and RL approaches clearly, covering data requirements, compute cost considerations, governance risks, and real-world deployment trade-offs, so you can make a confident, business-aligned decision.
Why Choosing the Right Fine-Tuning Method Matters
Large language models now power chatbots, knowledge assistants, and AI copilots across industries. Off-the-shelf models rarely meet enterprise needs for accuracy, compliance, or user experience.
Choosing the wrong adaptation method can cost time, money, and model performance.
Here’s what to consider when deciding between supervised fine-tuning and reinforcement learning approaches:
- Data Availability: SFT needs large, high-quality labeled datasets. Reinforcement Learning from Human Feedback (RLHF) and RFT, on the other hand, can work with smaller or evolving datasets.
- Task Complexity: Clear, structured tasks suit SFT. Tasks with human preferences or multi-step reasoning benefit from RL approaches.
- Adaptability: RL methods allow models to learn and adjust dynamically. SFT models remain static once trained.
- Resource Requirements: RL-based training is computationally heavy and may require human evaluators. SFT is more predictable and faster to deploy.
- Risk and Compliance: SFT provides consistent, reproducible results. RL approaches may need extra monitoring to avoid unexpected behaviors.
Understanding these factors helps you match your fine-tuning strategy to your goals, data, and resources.
Organizations looking to build reliable, high-performing AI systems can benefit from partnering with experienced AI teams like Relinns Technologies that support enterprises with end-to-end fine-tuning services and help them evaluate trade-offs, design the right training pipeline, and avoid costly experimentation.
Supervised Fine‑Tuning: The Fixed Data Approach
Supervised Fine-Tuning (SFT) is like teaching a well-read student to perform a specific job. You give it examples with clear answers, and it learns to replicate them.
Example: Teaching a model to recognize animals in photos. You show pictures of monkeys, lions, and elephants and label each one. Over time, it learns to identify each animal correctly in new images.
This approach works best when the instructions are straightforward, and the expected results are obvious (like sorting emails or summarizing reports). It’s reliable, fast, and predictable, but it depends on having a solid set of labeled examples.
How Supervised Fine‑Tuning Works
Here’s how the SFT process typically unfolds:
| Order-wise Step | What Happens | Why It Matters |
| Gather Labeled Data | Collect pairs of inputs and their correct outputs. | Gives the system concrete patterns to learn from |
| Set an Error Metric | Measure how far predictions are from the right answers. | Shows where adjustments are needed |
| Adjust Parameters | Fine-tune internal weights to reduce errors. | Improves performance step by step |
| Test Performance | Check results on new examples. | Ensures it generalizes and avoids memorization |
SFT is mostly a fixed-data approach. It follows the examples exactly and cannot explore alternative reasoning chains or adapt based on feedback after deployment.
Strengths and Limitations of Supervised Fine-Tuning
The key benefits and trade-offs of supervised fine-tuning include:
Strengths:
- Produces consistent, dependable results
- Quick to implement and efficient to run
- Doesn’t need complicated feedback mechanisms
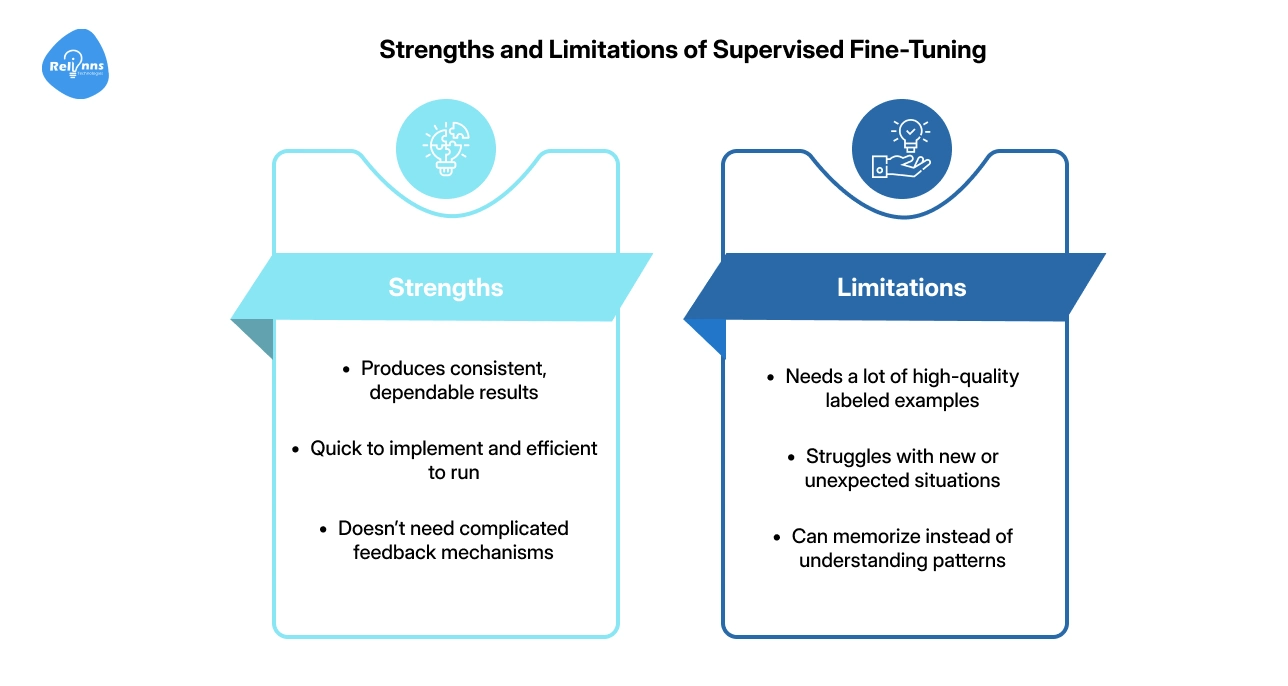
Limitations:
- Needs a lot of high-quality labeled examples
- Struggles with new or unexpected situations
- Can memorize instead of understanding patterns
SFT is a solid first step when answers are clear, and data is plentiful. It lays a strong foundation before moving to more adaptive methods, like reinforcement learning.
Reinforcement Learning from Human Feedback: The Adaptive Approach
Reinforcement Learning from Human Feedback (RLHF) teaches a model by showing it the results of its actions rather than giving fixed answers.
It’s the most widely used form of RL in modern language model training today, helping AI in fine-tuning language models from human preferences.
Example: Training a model to write polite, helpful responses in a customer support chatbot. Humans review answers and give positive feedback for clear, friendly responses. The model gradually improves based on these rewards rather than fixed rules.
So, RLHF allows models to learn from feedback and adapt to evolving expectations, rather than just memorizing fixed answers.
How RLHF Works
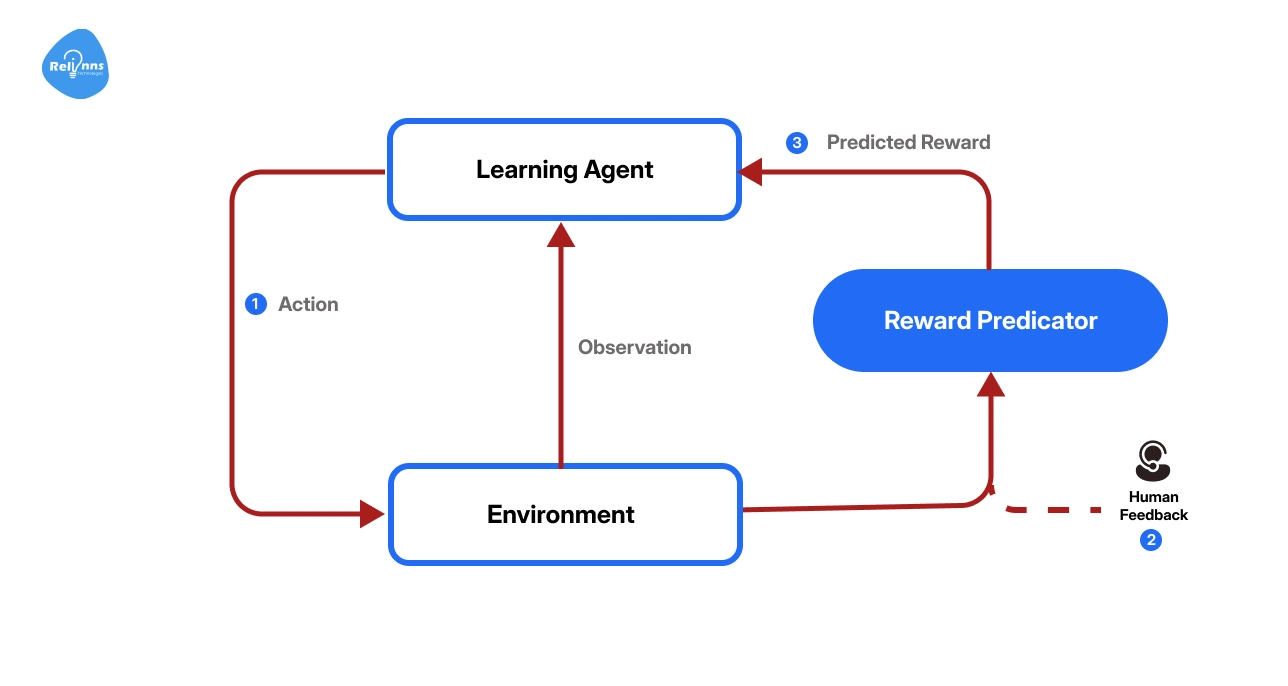
The following table showcases the step-by-step process of how the model explores, receives feedback, and improves over time:
| Order-wise Step | What Happens | Why It Matters |
| Set a Reward Function | Define what counts as a good output. | Guides the model on what to aim for |
| Generate Responses | The model tries different answers or actions. | Explores possible strategies |
| Score Outcomes | Humans or automated systems assign rewards. | Shows which behaviors are desirable |
| Adjust Strategy | The model updates parameters to maximize rewards. | Learns to improve over time |
Unlike SFT, RLHF is dynamic. It keeps learning as new feedback comes in and can handle tasks without clear “right answers”. Reinforcement Fine-Tuning (RFT) is similar but focuses on tasks where outputs can be objectively verified (doesn’t rely on humans).
Strengths and Limitations of RLHF
The main benefits and trade-offs of RLHF include:
Strengths:
- Encourages flexible thinking and generalization
- Aligns outputs with human preferences
- Continually adapts to new scenarios
Limitations:
- Computationally intensive
- Designing good reward rules is tricky.
- Balancing exploration of new strategies with refining known ones is challenging.
RLHF works best for situations where adaptability, human alignment, and creativity matter more than fixed answers.
Reinforcement Fine‑Tuning: A New Hybrid
Reinforcement Fine-Tuning (RFT) is a hybrid of supervised fine-tuning and reinforcement learning. The model works on clearly defined tasks, generating multiple answers for each prompt.
Unlike RLHF, RFT doesn’t need human feedback. It uses objective checks (like a compiler, math checker, or Sudoku validator) to score outputs automatically. The model adjusts itself to favor the best answers.
RFT differs from RLHF because it focuses on correct outcomes rather than human preferences. It differs from SFT because it learns from rewards instead of fixed labels, making it ideal when labeled data is scarce.
Example: Imagine teaching a model to solve Sudoku puzzles. Instead of giving pre-solved examples, the model tries its own solutions. A script checks the rules and rewards only correct answers. Over time, the model discovers strategies to solve new puzzles correctly, exploring possibilities on its own.
When Does RFT Shine?
RFT works best in situations like:
- No Labeled Data But Verifiable Results: Like code generation, where correctness can be checked automatically
- Limited Labeled Data: When you have fewer than 100 examples, SFT may overfit, but RFT learns general strategies from small datasets.
- Chain-of-thought Reasoning: Tasks requiring intermediate steps, like logical puzzles or multi-step problem solving, benefit from RFT’s iterative exploration.
RFT encourages the model to explore reasoning strategies and uncover solutions it might not have learned with SFT alone. However, it still needs a way to verify correctness and can be slower when datasets are large.
Supervised Fine-Tuning vs Reinforcement Learning: A Comparison
Choosing the right approach isn’t just about hype: it shapes how your model learns, adapts, and performs in the real world.
The table below breaks down the key differences between Supervised Fine-Tuning, RLHF, and RFT across critical factors, so you can see at a glance which approach fits your needs.
| Aspect | Supervised Fine-Tuning (SFT) | Reinforcement Learning & RLHF | Reinforcement Fine-Tuning (RFT) |
| Learning signal | Labeled examples | Rewards from human feedback | Rewards from verifiable outputs |
| Process | Offline; fixed dataset | Online; evolves via feedback | Online; generates candidates & scores |
| Data requirement | Large labeled datasets | Human preference data; often smaller | Verifiable outputs; small labeled data optional |
| Generalization | Risk of memorization | Encourages generalization | Promotes reasoning strategies |
| Implementation complexity | Lower; no reward function | High; requires reward design | High; requires verifiers & reward server |
| Compute cost | Moderate; stable training | High; multiple feedback loops | High; dynamic generation & scoring |
| Best suited tasks | Structured tasks with clear answers | Conversational AI, dynamic tasks | Tasks with verifiable correctness; small datasets |
| Limitations | Overfitting; limited adaptability | Reward design; cost; exploration challenges | Requires verifiers; slower on large data |
Understanding reinforcement learning vs supervised fine-tuning helps you choose the right strategy based on your data, task complexity, and business goals, without getting lost in the noise.
Pre‑Training, Fine‑Tuning, and Transfer Learning
Before fine-tuning, models go through pre-training, where they learn general patterns from massive amounts of data. Think of it as teaching a student the basics of language and reasoning.
In the pre-training vs fine-tuning process, fine-tuning adapts these pre-trained models to specific tasks. It’s like giving the student a focused project: summarizing reports, classifying emails, or answering customer questions.
Transfer learning, on the other hand, is a broader concept. It reuses knowledge from one task to help with a related task. Two common strategies of transfer learning are:
- Feature Extraction: Freeze most of the pre-trained model and train only a small new layer for the task. Works well with small datasets.
- Full Fine-tuning: Adjust some of the pre-trained layers along with the new task layer. Requires more data but gives higher accuracy.
In practice, many teams combine transfer learning and fine-tuning. Transfer learning suits small datasets and limited compute, whereas fine‑tuning suits larger, related datasets and requires more resources.
Pre-training provides the foundation, and task-specific fine-tuning delivers practical, reliable results.
Practical Use Cases of SFT and RL
Different AI tasks benefit from different approaches.
Choosing between Supervised Fine-Tuning (SFT) and RL-based methods (RLHF/RFT) depends on the type of data, adaptability needed, and the complexity of the task.
When SFT Makes Sense
SFT is ideal for predictable, structured tasks where large labeled datasets are available.
The table below displays these key scenarios:
| Task | Why SFT Works |
| Email Classification & Filtering | Large labeled datasets enable reliable spam detection. |
| Document Summarization & Q&A | Clear input-output pairs allow structured learning. |
| Domain Adaptation | Thousands of support transcripts help align tone and knowledge base. |
| Time-critical Deployment | Predictable training fits regulated schedules and release windows. |
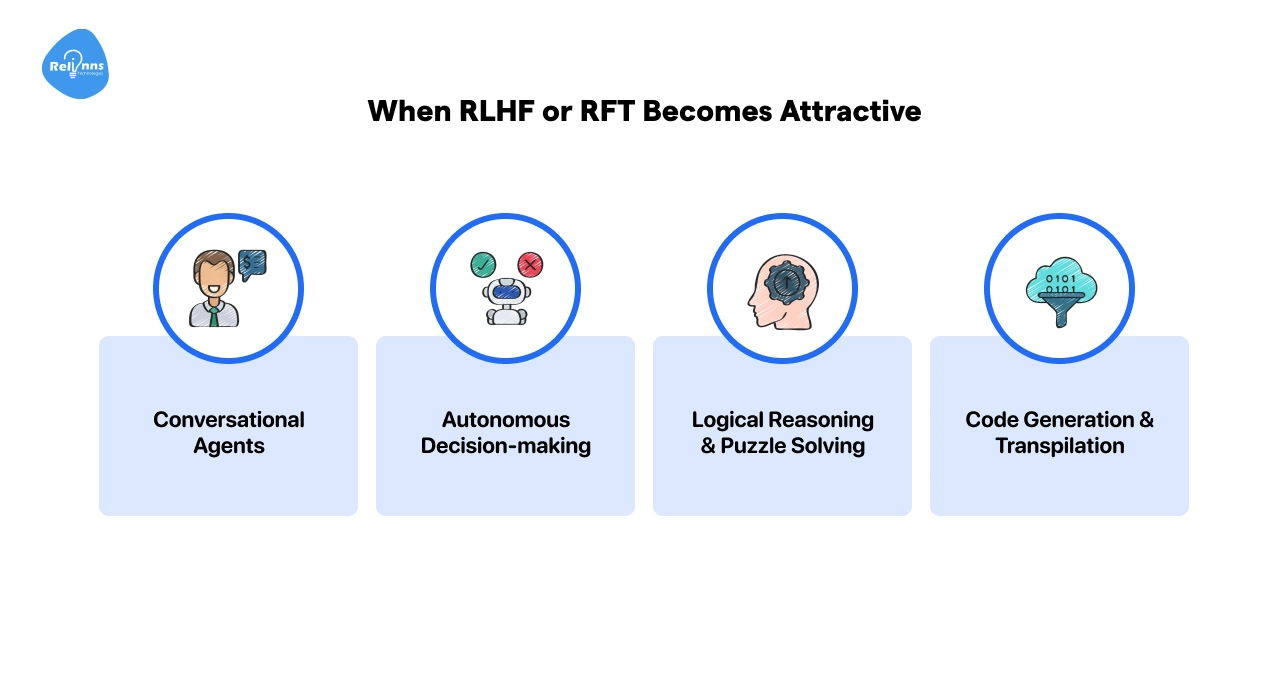
When RLHF or RFT Becomes Attractive
RL-based methods shine when flexibility, exploration, and human-aligned behavior matter.
Use them for tasks such as:
- Conversational Agents: Chatbots need dynamic alignment with user intent. RLHF helps optimize helpfulness and tone.
- Autonomous Decision-making: Robotics or vehicles benefit from continuous feedback in unpredictable environments.
- Logical Reasoning & Puzzle Solving: RFT improves performance on chain-of-thought tasks, even with limited examples.
- Code Generation & Transpilation: Verifiable outputs allow models to improve without labeled datasets.
Transfer Learning vs Fine-Tuning
For smaller datasets or limited resources, feature extraction (transfer learning) may be enough.
Fine-tuning layers adds accuracy when datasets are larger or closely match the pre-training domain, at the cost of higher compute.
Planning Costs, Security, and Operations for SFT & RL
Adopting SFT, RLHF, or RFT isn’t just a technical choice: it impacts budgets, compliance, and day-to-day operations.
Addressing these factors helps teams plan effectively and avoid surprises.
Cost and Resource Planning
Managing resources effectively is key to a successful deployment. Consider the following:
- Data Labeling Costs: SFT needs large labeled datasets. Budgets must cover annotation and quality checks.
- Compute Cost: RLHF and RFT require multiple rounds of generation, scoring, and optimization. GPU hours and infrastructure can add up quickly.
- Human Feedback: RLHF depends on trained evaluators. Proper training reduces bias and ensures consistent guidance.
- Verification Functions: RFT needs automated systems (like compilers or test suites) to score outputs accurately.
Security and Compliance
Keeping your models secure and compliant protects both data and reputation. Key points include:
- Data Privacy: All datasets must be anonymized to prevent leaks.
- Reward Hacking: Poorly designed rewards can lead to unintended behaviors. Regular adversarial testing helps catch misalignments.
- Regulatory Constraints: Human feedback introduces subjectivity. Documenting processes ensures fairness and auditability.
- Version Control: Online learning requires careful tracking of policies and reward functions to reproduce results reliably.
Operational Deployment
Smooth day-to-day operation ensures consistent performance and reliability:
- Latency Considerations: RL models generate multiple candidates, which can slow responses. Caching strategies help maintain performance.
- Monitoring: Track reward distributions, policy changes, and user satisfaction to spot drift early.
- Rollback Plan: Keep the ability to revert to a stable SFT model if RL experiments degrade performance.
Careful planning across cost, compliance, and operations ensures your AI models remain efficient, secure, and reliable.
Organizations that proactively address these factors reduce deployment risks and avoid expensive rework later.
Many businesses partner with teams with experience in fine-tuning pipelines, reward design, and governance frameworks like Relinns Technologies to streamline fine-tuning processes and ensure models are production-ready from day one.
Challenges in Using SFT & RL Approaches
Both SFT and RL-based methods have limitations that affect performance, cost, and reliability. Knowing them helps teams plan effectively and implement safeguards.
| Approach | Key Challenges | What It Means | Mitigation / Solutions |
| Supervised Fine-Tuning (SFT) | Dataset bias | Models may inherit biases in training data. | Use diverse, representative datasets; perform bias audits. |
| Poor generalization | Overfitting can fail on edge cases. | Regular validation, augment data, monitor edge performance | |
| Labeling ambiguity | Subjective answers are hard to capture. | Use clear guidelines for labeling; review ambiguous cases. | |
| RLHF / RFT | Reward design | Misaligned rewards can cause unintended behavior. | Carefully design reward functions; test with pilot runs. |
| Resource intensity | Training loops are expensive; tuning errors multiply costs. | Optimize training pipelines; monitor compute usage. | |
| Human bias | Feedback may reflect individual preferences. | Use multiple evaluators and consensus scoring. | |
| Verification limitations | RFT requires objective verifiers; not all tasks can be scored. | Limit RFT to tasks with verifiable outcomes; automate checks where possible. |
Tip: Many challenges can be reduced by starting small, monitoring results closely, and combining SFT for stability with RL/RFT for adaptability.
Decision Checklist: When to Use SFT, RLHF, or RFT
Choosing the right method depends on your data, constraints, and success metrics. Here’s a simple decision guide.
Use SFT when:
- You have large, high-quality labeled datasets.
- The task has clear, objective outputs.
- Stability, traceability, and predictable performance matter more than adaptability.
This is often the right choice for regulated environments and structured enterprise workflows.
Use RLHF when:
- User preference defines success.
- Tone, helpfulness, or alignment directly impact outcomes.
- The environment changes frequently, and you can support continuous feedback loops and higher compute costs.
RLHF is ideal when human preference drives success.
Use RFT when:
- Labels are limited, but correctness can be verified automatically.
- The task benefits from reasoning, exploration, or multi-step problem solving.
RFT fits tasks where correctness can be automatically verified.
In practice, many teams combine methods: starting with SFT for stability, then adding RLHF or RFT where adaptability or deeper reasoning creates measurable value.
Wrapping Up
Supervised fine‑tuning, reinforcement learning from human feedback, and reinforcement fine‑tuning, each of which provides distinct pathways for adapting LLMs.
The choice hinges on data availability, task complexity, resource constraints, and business objectives. SFT delivers reliable performance with low complexity; RLHF aligns models with human preferences but demands careful reward design; RFT bridges the gap when labels are scarce and reasoning matters.
Rather than chasing hype, leaders should evaluate the operational impact of each method and adopt a tailored strategy. By understanding the trade‑offs, businesses can unlock scalable, responsible AI solutions that support their organisation’s goals.
Frequently Asked Questions
What is Supervised Fine-Tuning?
Supervised fine-tuning (SFT) adapts a pre-trained model using labeled prompt–response pairs. The model learns by minimizing the difference between its predictions and the correct outputs for a specific task.
How Does Reinforcement Learning from Human Feedback Differ from SFT Fine-Tuning?
RLHF trains models using reward signals from human evaluators instead of fixed labels. It optimizes for preference and alignment, while SFT learns from predefined correct answers.
When Should I Consider Reinforcement Fine-Tuning?
Use RFT when labeled data is limited, but outputs can be verified automatically, such as code or math tasks. It works well for reasoning and multi-step problem-solving.
How Does Transfer Learning Relate to Fine-Tuning?
Transfer learning reuses a pre-trained model’s features for a new task. Fine-tuning goes further by updating some model layers to improve task-specific performance.
What are the Main Trade-Offs Between SFT and RL?
SFT is simpler and more predictable, but it needs large labeled datasets. RL methods are more adaptable and aligned with preferences but require higher compute and careful reward design.
Do RL Methods Compromise Data Privacy?
Not inherently. However, RLHF may involve user feedback data. Proper anonymization, secure storage, and governance controls are essential to maintain privacy and compliance.
Can I Combine SFT, RLHF, and RFT?
Yes. Many teams start with SFT for stability, then apply RLHF or RFT where adaptability or reasoning improvements are needed.
Is RLHF Better than Supervised Fine-Tuning?
Neither is universally better. SFT works best for structured tasks with clear answers, while RLHF is better for preference-driven or dynamic environments.



