

Optimizing RAG in Domain Chatbots with Reinforcement Learning
Date
Feb 20, 26
Reading Time
10 Minutes
Category
Generative AI
Share
.webp)
Most RAG chatbots don’t break.
They just underperform in ways that are easy to miss.
Retrieval often pulls in too much context. Tokens are lost, and accuracy drops. Adding a larger LLM or relying on a static RAG pipeline doesn’t help either.
This is where reinforcement learning reshapes what RAG means for chatbots. Instead of fixed rules, the system learns which retrieval actions actually improve answers. Over time, this dynamic approach optimizes cost, relevance, and accuracy.
Notably, such decisions matter even more in domain-specific chatbots, as mistakes become more expensive. Systems need to plan, adapt, and choose actions deliberately.
This guide explains reinforcement learning for optimizing RAG for domain chatbots and why agentic RAG is central to building smarter systems.
Why Do Domain-Specific Chatbots Need RAG?
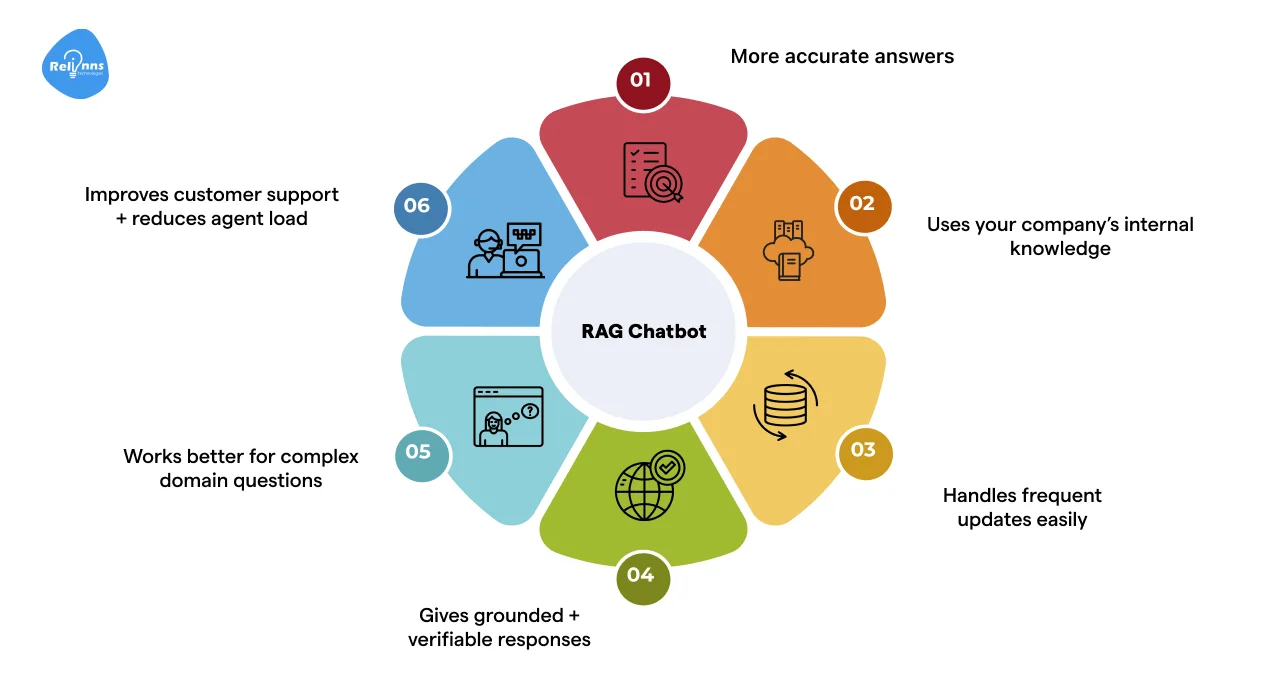
Domain-specific chatbots face complex queries and industry-specific language. RAG helps them give accurate, relevant answers by combining retrieval and generation.
For these chatbots, this means answers are more accurate, context-aware, and cost-efficient.
Understanding how retrieval and generation work together is key to building RAG model chatbots that consistently deliver useful answers.
How RAG Combines Retrieval and Generation in LLM Chatbots
A RAG LLM chatbot works in two steps.
- Step 1 → The retrieval module searches a knowledge base for the right information.
- Step 2 → The LLM creates a response using that context.
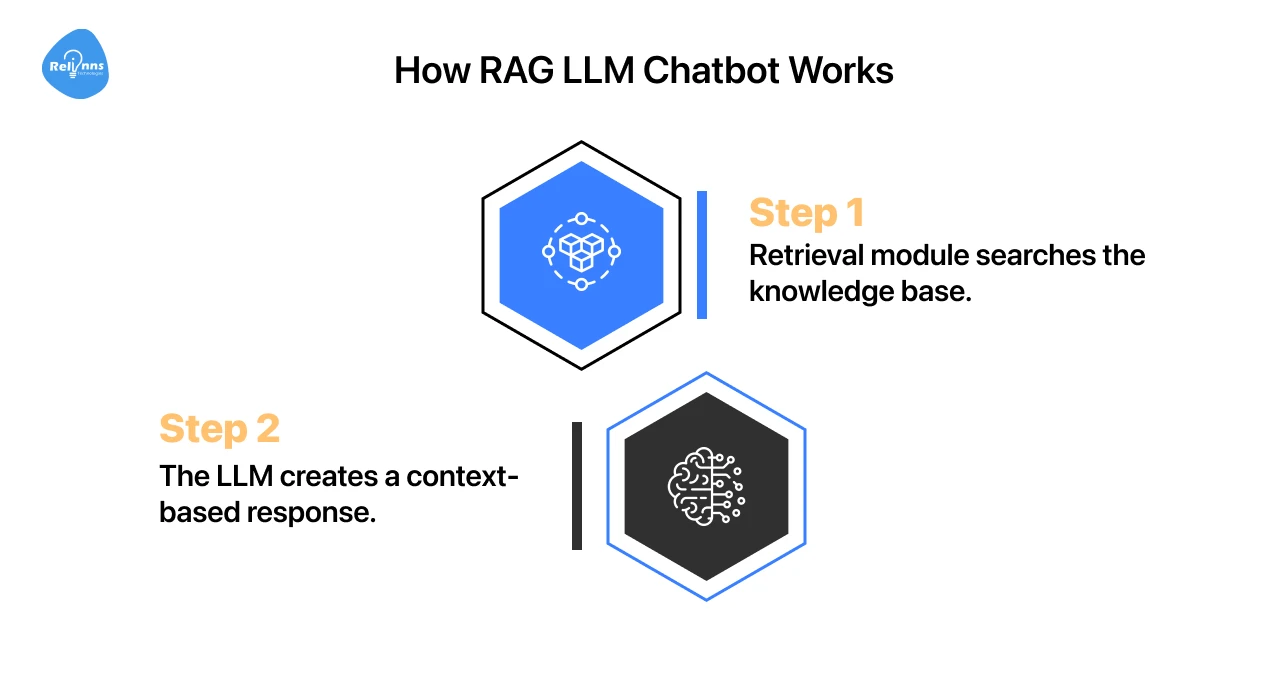
This approach reduces mistakes, keeps answers relevant, and sounds natural.
How Domain-Specific RAG Chatbots Perform Better
Domain-specific chatbots know the language and rules of their field.
They retrieve exactly what’s needed, which makes them faster and more reliable than generic bots.
Here’s a breakdown of how these chatbots work across different domains.
Capitalizing on these benefits, many teams partner with AI solutions providers like Relinns Technologies to build custom domain-specific chatbots tailored to their industry.
Whether it’s finance, healthcare, e-commerce, or tech support, Relinns ensures your chatbot understands your domain, handles queries efficiently, and scales with your business needs.
Limitations of Traditional RAG Models in Real-World Use
Old-school RAG models can pull too much or too little info.
That wastes tokens, slows responses, lowers precision, and sometimes misses the point. Static pipelines also struggle with complex queries, making them less useful for real-world domain chatbots.
This calls for a smarter, adaptive approach that can learn which retrieval actions actually improve answers.
Reinforcement Learning for Smarter RAG Pipelines
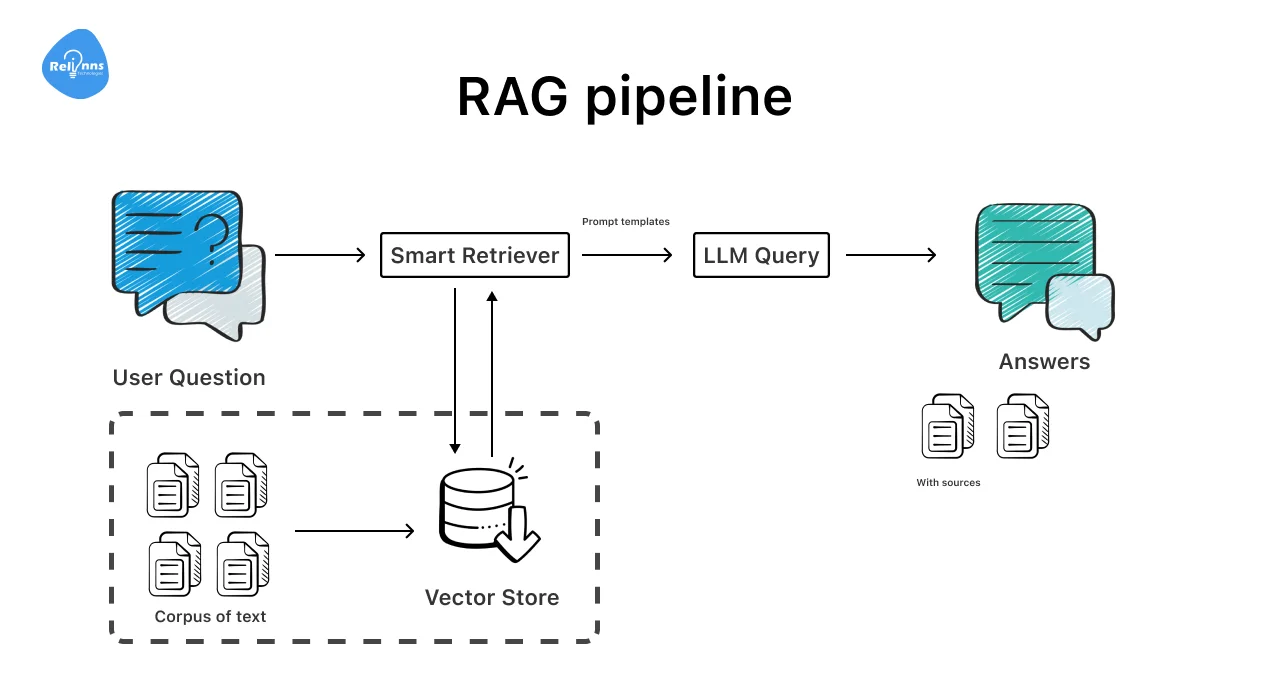
RL (Reinforcement Learning) improves RAG pipelines by teaching them which retrieval actions actually help.
Instead of fixed rules, the system learns from what works. This makes domain chatbots more dependable, relevant, and economical.
Some important factors to look at include retrieval quality, answer applicability, and token efficiency.
How RL Policy Models Control RAG Retrieval Decisions
RL policy models decide what information the chatbot should pull out.
By evaluating past retrievals and measuring their impact on answer quality, the system learns which documents improve answers and which are unnecessary.
This makes RAG chatbots more focused, consistent, and effective at delivering helpful responses.
Reducing Token Usage and Costs with RL-Based Optimization
By selecting only relevant context, RL reduces token usage, saving computational resources.
Instead of blindly retrieving everything, the chatbot retrieves smarter, not more.
This helps maintain high-quality answers while cutting unnecessary processing.
Simplifying RL Training for RAG Using Rewards and Feedback
RL training uses rewards and feedback to teach the chatbot what good answers look like.
Positive outcomes reinforce effective retrieval choices, while mistakes guide adjustments. This loop helps RAG pipelines improve continuously without heavy or extensive manual tuning.
Adapting to Changing Data in Real Time
RL also allows RAG chatbots to adapt as knowledge bases change.
When new documents are added or old ones are updated, the system relearns which sources matter most. This ensures answers remain current, reliable, and useful, even in fast-moving domains like healthcare or finance.
Thus, by combining focused retrieval, smart token usage, feedback-driven learning, and real-time adaptation, RL ensures domain chatbots perform better on complex queries and sets the stage for agentic RAG.
Agentic RAG: Extending Reinforcement Learning Optimization
While standard RAG relies on fixed rules, agentic RAG introduces active decision-making into the pipeline, guided by reinforcement learning.
The system evaluates which actions will actually yield the best response instead of just following retrieval rules.
For domain-specific chatbots, this shift makes them adaptive problem solvers capable of handling nuanced, high-stakes questions.
What Defines Agentic RAG
In a standard LLM-powered chatbot, retrieval and generation are linear.
However, agentic RAG treats them as an iterative process. The system, therefore, “thinks” before it acts, assessing multiple paths for locating the most relevant context.
- Dynamic Strategy: Unlike static RAG, which pulls data in one shot, an agentic system adjusts strategies on the fly.
- Active Refinement: It prioritizes specific sources, refines search queries, and even determines when to ask follow-up questions.
This makes agentic RAG chatbots more reliable in real-world environments, where data is messy or queries are ambiguous.
Solving Complex, Multi-Step Queries with Agentic RAG
Agentic RAG is most effective when a query requires multiple steps, deep reasoning, or data from multiple silos.
Consider a healthcare chatbot tasked with a complex patient inquiry.
To provide an accurate answer, it may need to: Review patient history → Consult specific treatment guidelines → Cross-reference recent lab results.
An agentic system plans each retrieval step, chooses the most useful sources, and sequences actions for the best result.
This structured approach reduces “hallucinations”, minimizes token waste, and produces answers that are thorough and clear.
The Bottom Line: Combining RL with an agentic approach helps chatbots proactively anticipate user needs, adapt to changing data, and make informed decisions without constant human oversight.
This makes them ideal for industries like finance, healthcare, and tech support, where accuracy and multi-step reasoning matter most.
Where RL-Optimized RAG Chatbots Deliver Real Value
RL optimization is what moves RAG from a promising prototype to a production-ready asset.
They show real value in daily use by improving answer quality, reducing waste, and adapting to how people actually ask questions.
Here are the areas where RL-optimized RAG delivers the strongest impact.
Customer Support and FAQ Chatbots
Customer support is where weak RAG setups fail fast. Questions repeat, but phrasing changes. Static retrieval pulls too much context or misses key details.
RL changes this.
By avoiding content that adds noise, the chatbot learns which documents resolve issues quickly. Over time, answers become more consistent and easier to trust.
For FAQ and support flows, this means:
- Faster responses with less context
- Fewer follow-up questions
- Lower token usage per conversation
A well-tuned LLM RAG chatbot can handle billing questions, product help, and account issues without sounding robotic or guessing. This makes support teams leaner and customers less frustrated.
Real-World Impact: RL-Optimized RAG by Industry
In high-stakes industries, “close enough” isn't good enough for an AI response.
RL (Reinforcement Learning) allows RAG systems to evolve beyond static search, learning from every interaction to prioritize the most helpful sources.
Here is how RL-optimized RAG delivers precision where it’s needed most:
In these domains, mistakes are costly. RL helps the chatbot learn which sources lead to correct answers and which ones don’t.
At this stage, deeper choices like how knowledge is embedded and how the system responds when a query falls outside its domain separate robust RAG systems from fragile ones.
Advanced RAG Strategies: Embedding Models and Out-of-Domain Queries
As RAG systems mature, the focus shifts from “does it work?” to “how reliably does it perform?”
Two critical factors determine this: the precision of your embedding models and how gracefully the system handles questions it isn’t trained to answer.
Both directly affect answer quality and trust.
Choosing the Right Embedding Models for Domain RAG
Embedding models decide how information is indexed and retrieved.
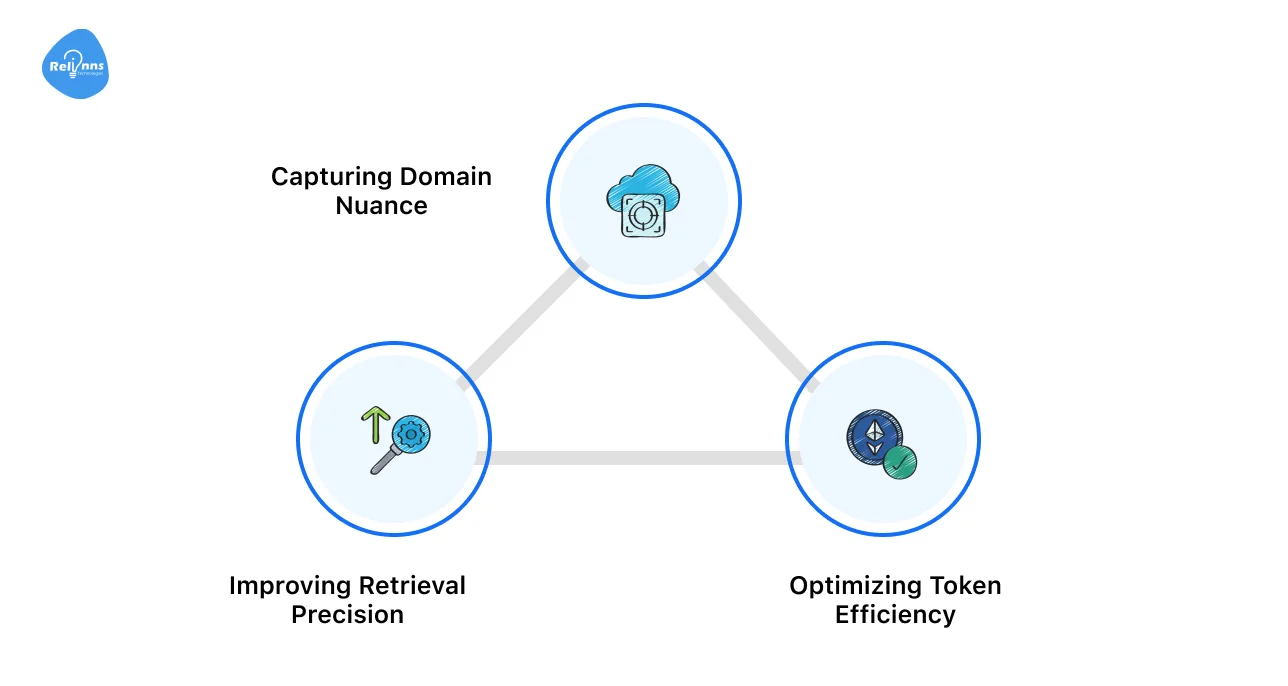
While generic models are fine for basic tasks, domain-specific chatbots require a more nuanced approach. These work best for:
- Capturing Domain Nuance: In specialized fields, word meaning changes with context. A “strike” means something very different to a labor lawyer than it does to a geologist. Domain-tuned embeddings capture these subtle shifts in intent.
- Improving Retrieval Precision: High-quality embeddings ensure the system pulls only the most relevant documents. This reduces “noise” and prevents the LLM from getting distracted by irrelevant data.
- Optimizing Token Efficiency: By retrieving cleaner, more accurate context, you send fewer unnecessary tokens to the LLM. This lowers operational costs and results in faster, more direct responses.
Handling Out-of-Domain Queries Gracefully
No matter how specialized your chatbot is, users will eventually ask questions that fall outside its expertise.
Handling these “edge cases” is what separates a prototype from a professional-grade tool.
- Avoiding the “Confidence Trap”: Traditional RAG systems often try to force a match even when they don’t have the data. This leads to confident but incorrect answers (hallucinations) that can damage your brand’s credibility.
- Implementing High-Confidence Thresholds: Advanced RAG setups use confidence scoring to detect when a query is “Out-of-Domain”. If the match is too low, the system is trained to stop instead of guessing.
- Graceful Deflection and Routing: Rather than a dead-end “I don't know,” an RL-optimized system can ask clarifying questions to narrow the search, route the user to a human agent or a different resource, and explain its limitations clearly to maintain user trust.
- Continuous Boundary Learning: Using Reinforcement Learning, the system learns from these Out-of-Domain interactions over time, getting better at defining the line between what it knows and what it doesn’t.
Once retrieval quality and system boundaries are under control, the real benefits come from reducing cost, especially in how RAG systems decide what to retrieve, when to retrieve, and when not to act at all.
How Reinforcement Learning Reduces RAG Costs Beyond Tokens
Token savings are only part of the story.
Reinforcement learning helps RAG systems cut costs across retrieval, compute, and retries, by learning which actions are worth taking and which aren’t.
Dynamic Cost Control in RL-Optimized RAG Pipelines
Most RAG pipelines treat every query the same. Retrieve context. Generate an answer. Move on.
RL breaks that pattern. The system learns to scale its effort based on the question. Simple queries trigger lightweight flows. Harder ones get deeper retrieval only when it’s needed.
Over time, the chatbot avoids extra searches, pulls shorter context, and stops once it has enough information.
For a production RAG LLM chatbot, this means faster replies and decreased run costs without hurting output quality.
Cutting Retrieval Costs with Smarter RL Reward Models
RL reward models don’t just care about good answers. They also watch the cost.
Retrieval actions that improve outcomes are rewarded.
The table below shows how an RL-optimized RAG pipeline controls retrieval costs more effectively than static setups.
This is why reinforcement learning for optimizing RAG for domain chatbots delivers savings beyond token control.
Strategic Retrieval Suppression for Low-Value Queries
RL also learns when retrieval adds no real benefit. For greetings, confirmations, or known intents, the system can skip retrieval entirely.
Avoiding low-value searches reduces database load and compute costs. It also speeds up responses. The RAG LLM chatbot thus becomes not just cheaper to run, but smarter about when effort is justified.
Many businesses work with AI development companies like Relinns Technologies that build custom domain-specific chatbots leveraging reinforcement learning to optimize RAG pipelines.
Proven development practices ensure your chatbot delivers precise and relevant responses while keeping costs under control.
Partnering with Relinns for Custom, RL-Optimized Domain Chatbots
Relinns Technologies builds custom domain-specific chatbots that harness reinforcement learning to optimize RAG pipelines.
Their end-to-end services cover discovery, architecture, BOT training, QA, and post-launch support. These chatbots handle business-critical tasks like customer queries, bookings, and personalized suggestions across platforms such as WhatsApp, Instagram, Telegram, and Shopify.
By integrating RL, Relinns ensures efficient retrieval, reduced operational costs, and high-fidelity responses. It also maintains industry compliance while delivering scalable, reliable solutions that align with real-world business needs.
Wrap Up
A good RAG chatbot isn’t built by throwing more data or a bigger model at the problem.
It’s built by making better decisions.
Reinforcement learning helps RAG systems learn what actually improves an answer and what doesn’t. It reduces unnecessary retrieval, controls costs, and improves answer quality.
This is especially important for domain-specific chatbots, where accuracy and compliance matter.
When reinforcement learning is combined with agentic RAG, chatbots handle complex questions with more care and fewer mistakes. The result is a RAG-based chatbot that feels reliable, scales cleanly, and delivers real value in everyday use.
Frequently Asked Questions
How can RL-based RAG optimization benefit businesses?
RL improves retrieval precision, reduces waste, and delivers more reliable, domain-specific answers at lower operational cost.
What is Agentic RAG, and how does it differ from traditional RAG models?
Agentic RAG plans and adapts retrieval actions, while traditional RAG follows a fixed, one-step retrieval and generation flow.
What are the cost-saving benefits of RL in chatbots?
RL cuts token usage, avoids unnecessary retrieval, reduces retries, and lowers compute costs without sacrificing response quality.
Is reinforcement learning necessary for domain-specific chatbots?
Not always. However, it can be critical for complex domains where accuracy, compliance, and adaptive retrieval matter.
Can RL-optimized RAG chatbots adapt to changing data?
Yes. RL enables continuous learning, allowing retrieval strategies to adjust as knowledge sources evolve.



